I Reviewed 1,000s of Opinions on gRPC

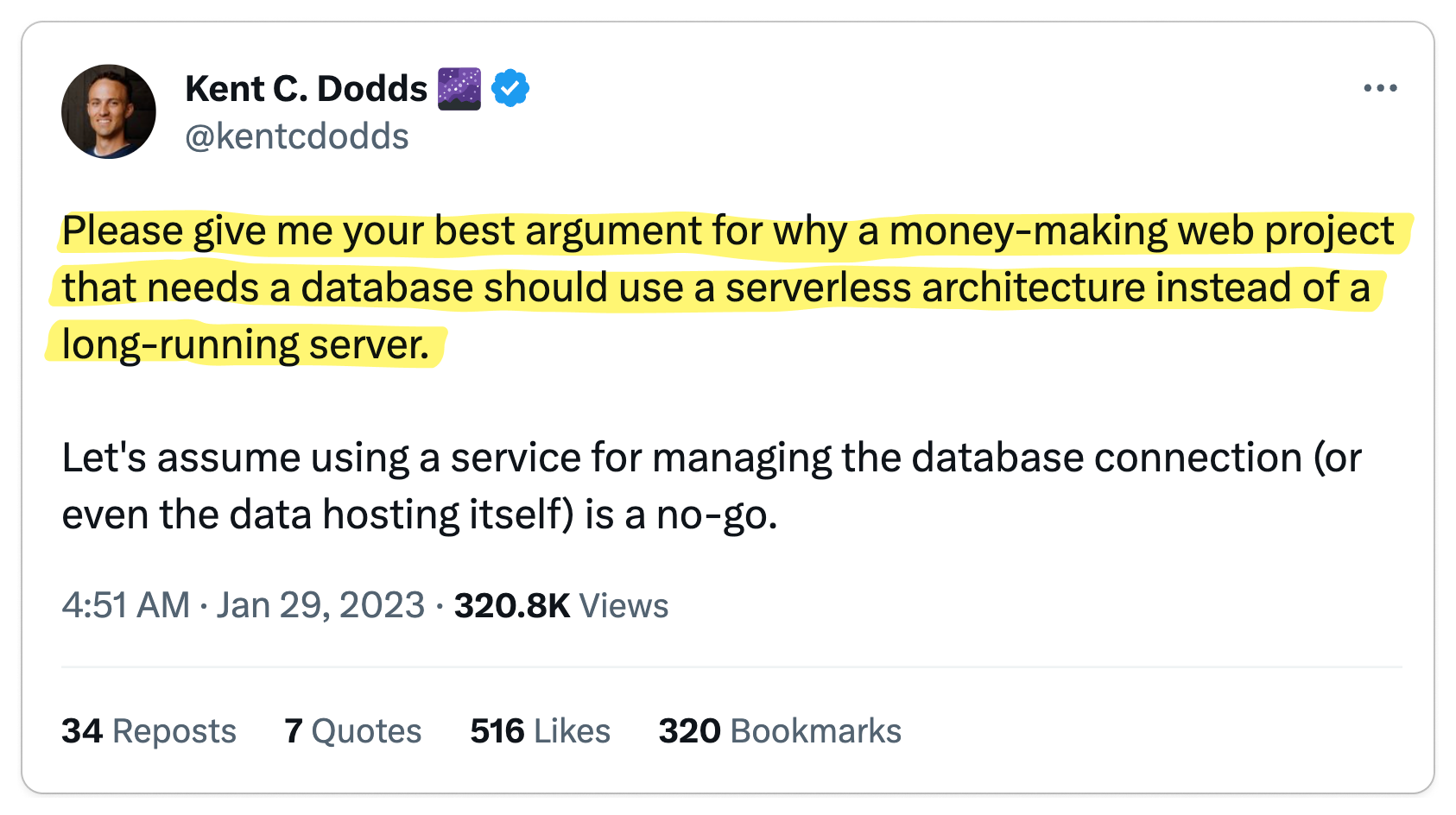
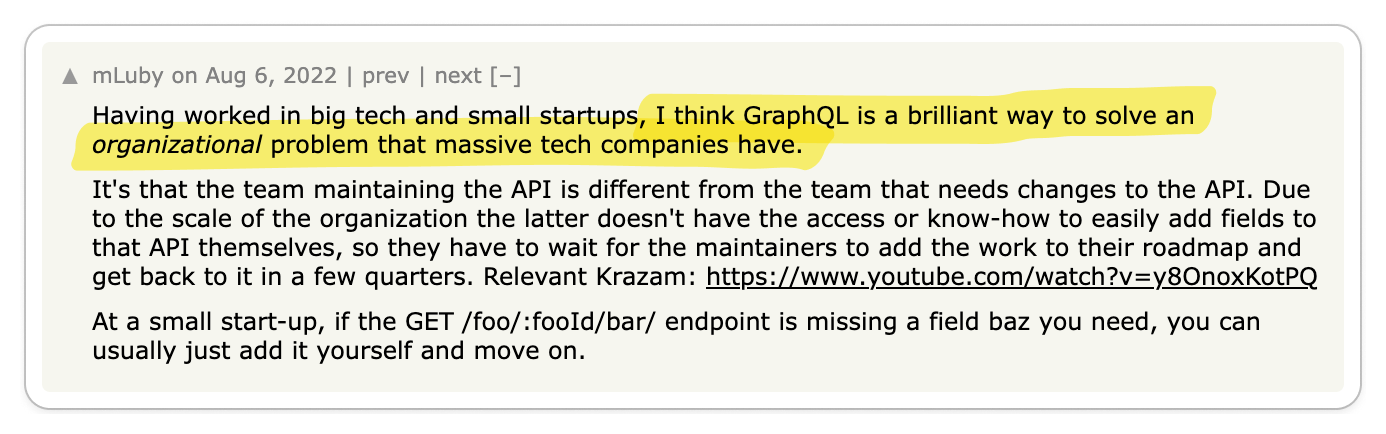
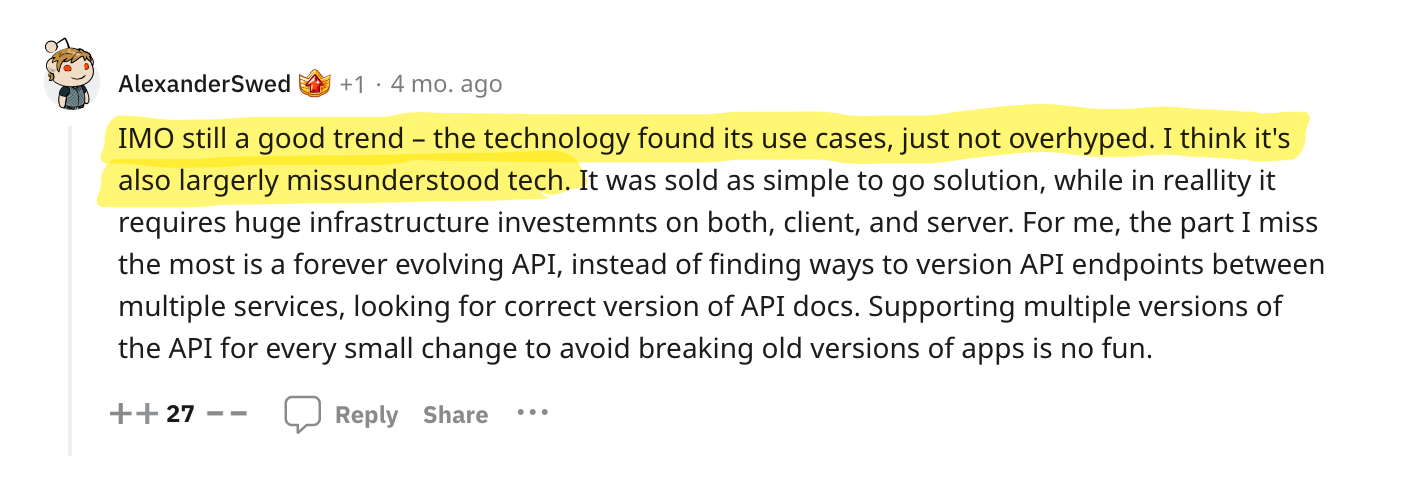
It is no secret that gRPC is widely adopted in large software companies. Google originally developed Stubby in 2010 as an internal RPC protocol. In 2015, Google decided to open source Stubby and rename it to gRPC. Uber and Netflix, both of which are heavily oriented toward microservices, have extensively embraced gRPC. While I haven't personally used gRPC, I have colleagues who adore it. However, what is the true sentiment among developers regarding gRPC?
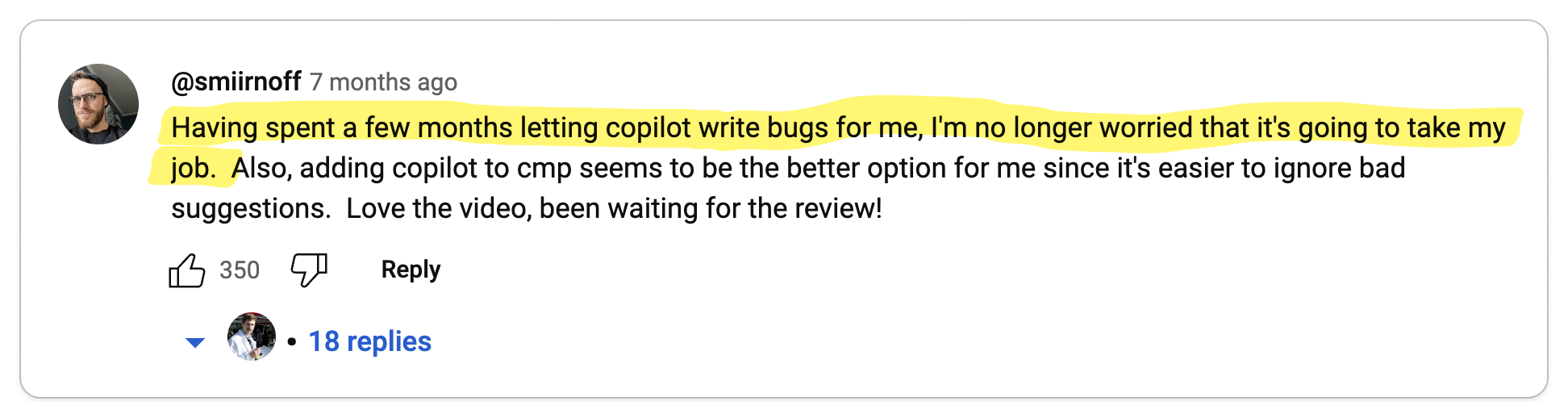
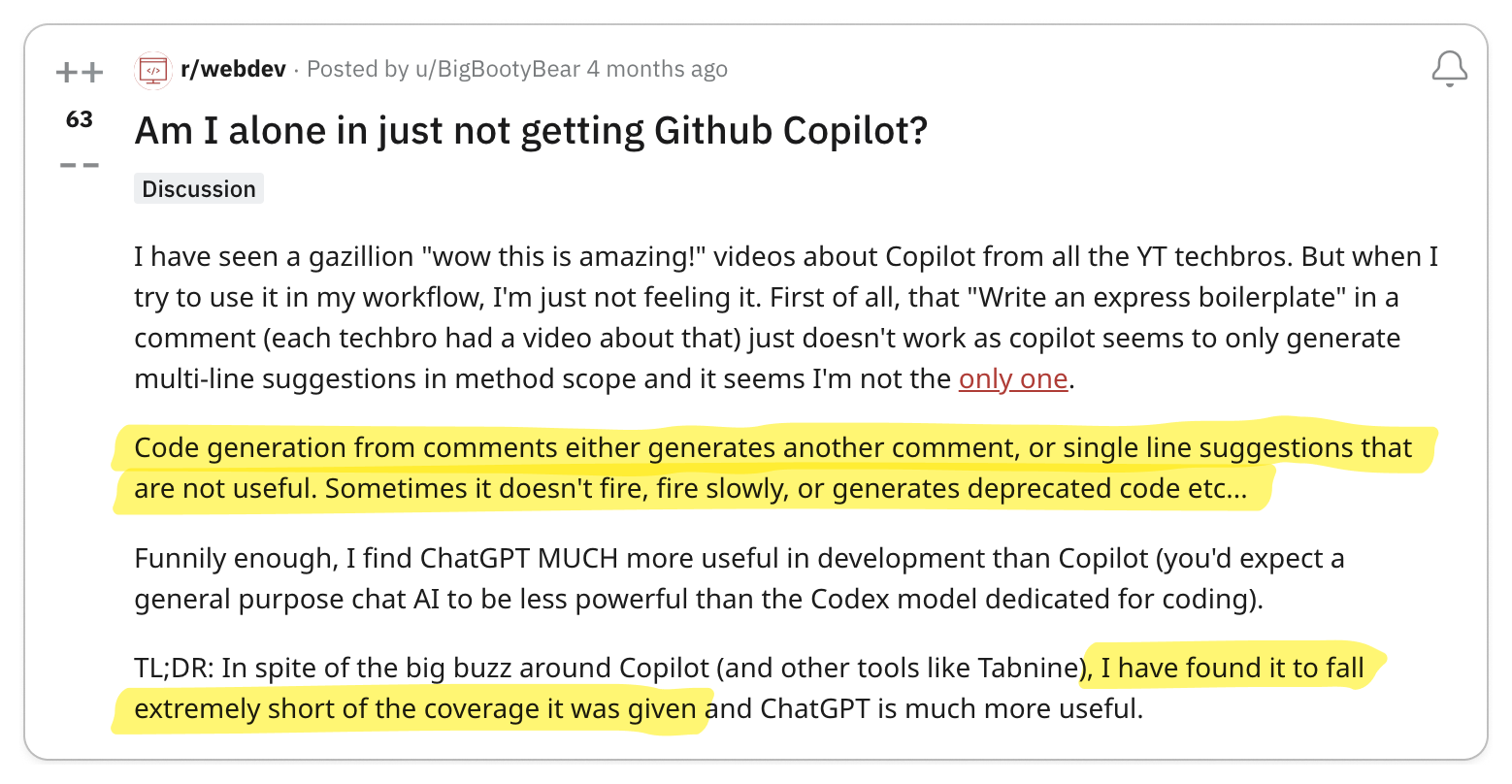
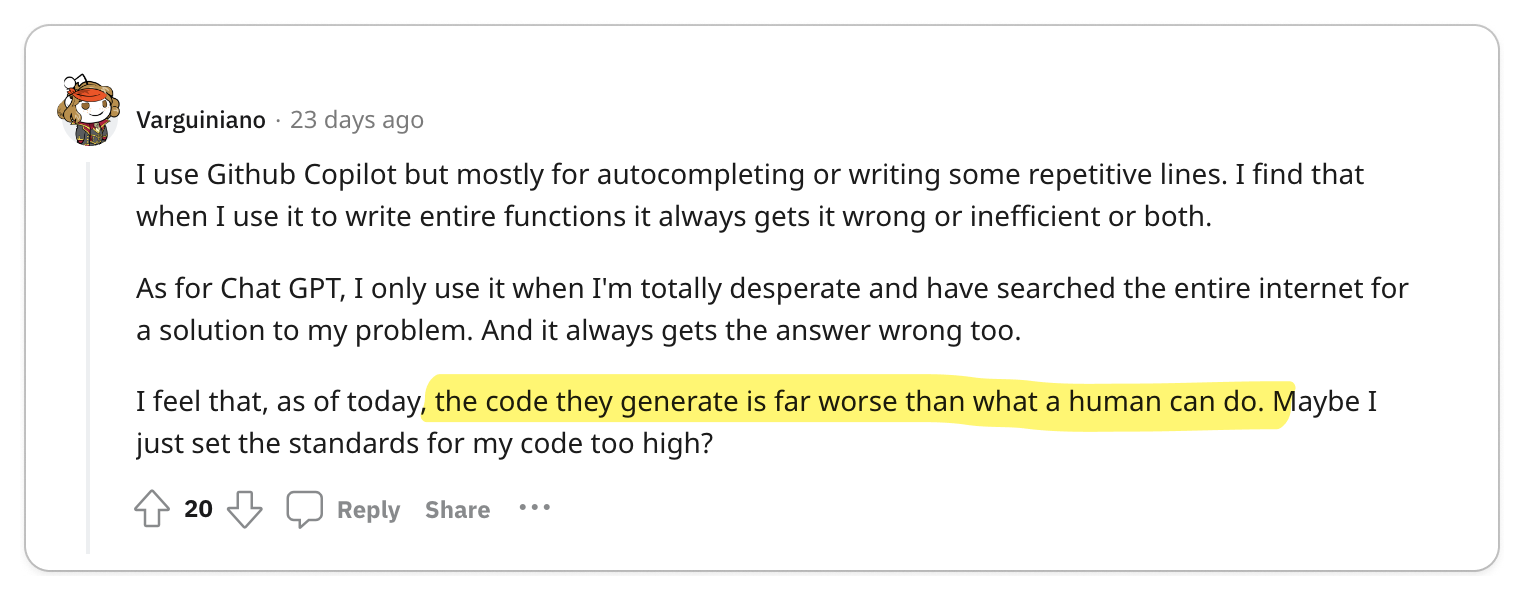
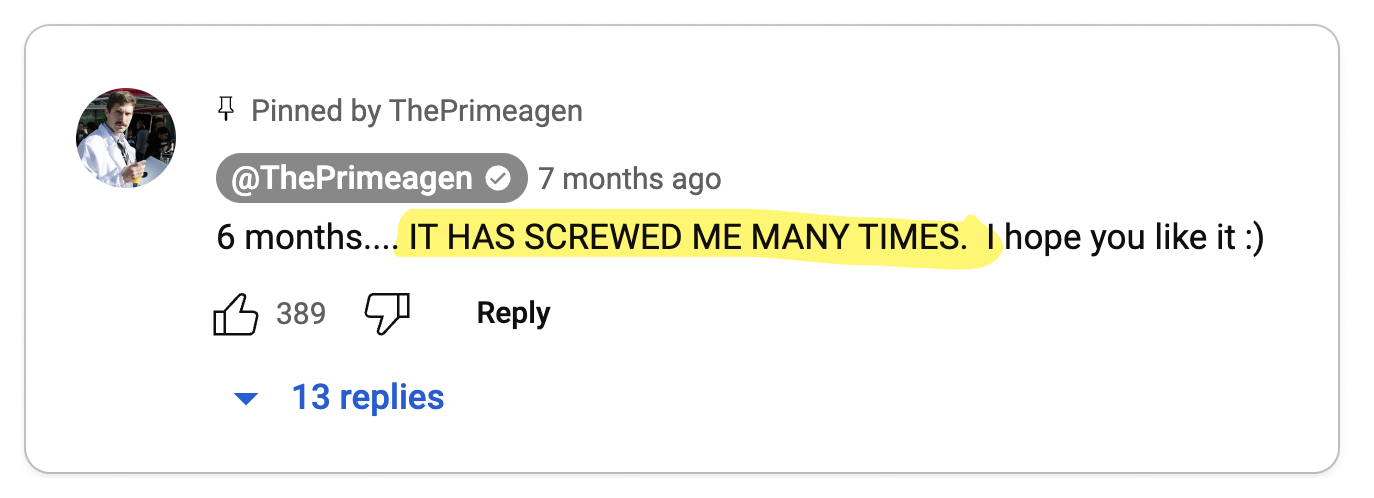
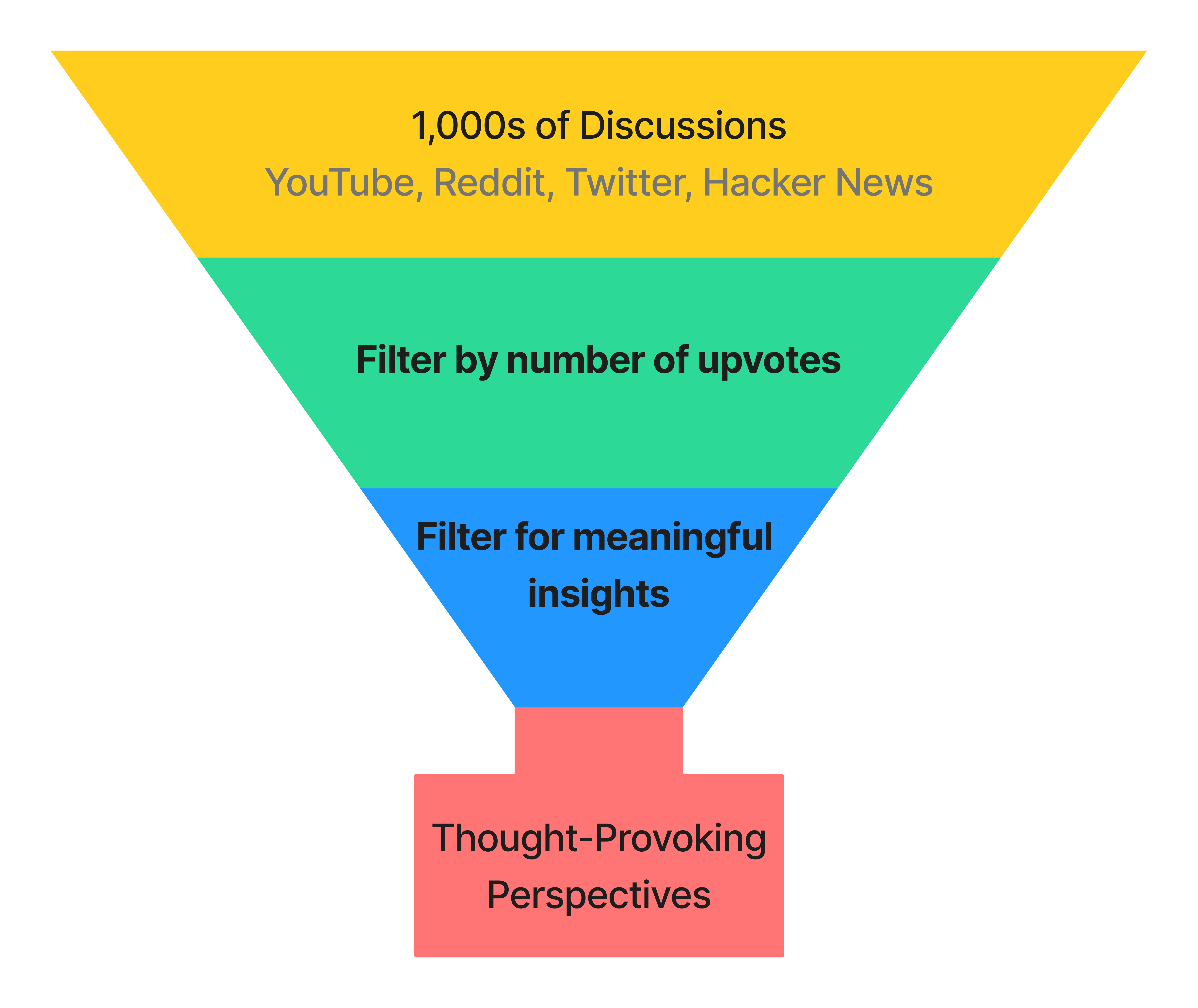
To find out, I went to where developers live: Reddit, Twitter, Hacker News, and YouTube. I parsed 1,000s of discussions and synthesized my findings in this article, striving to present only thought-provoking opinions.
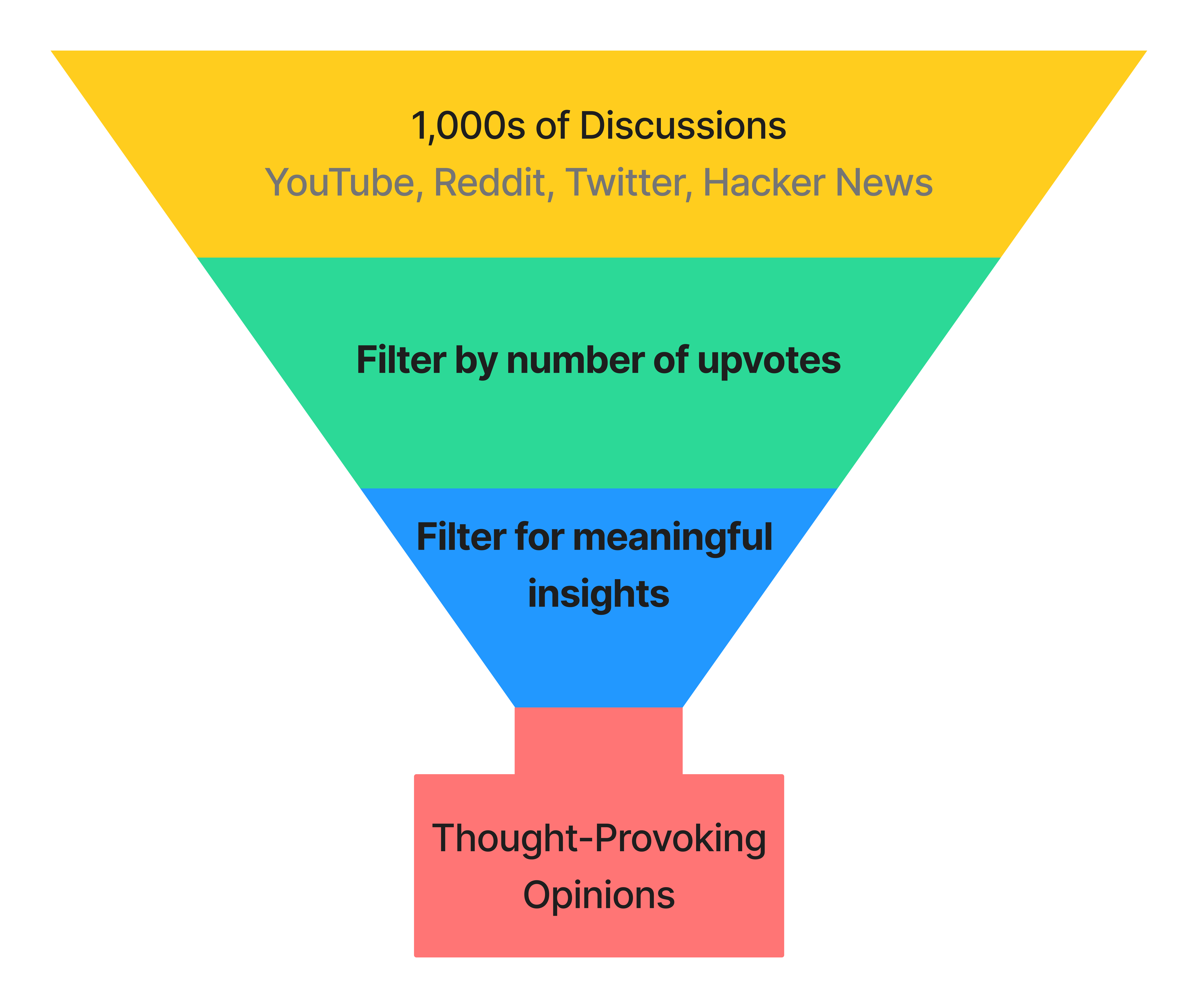
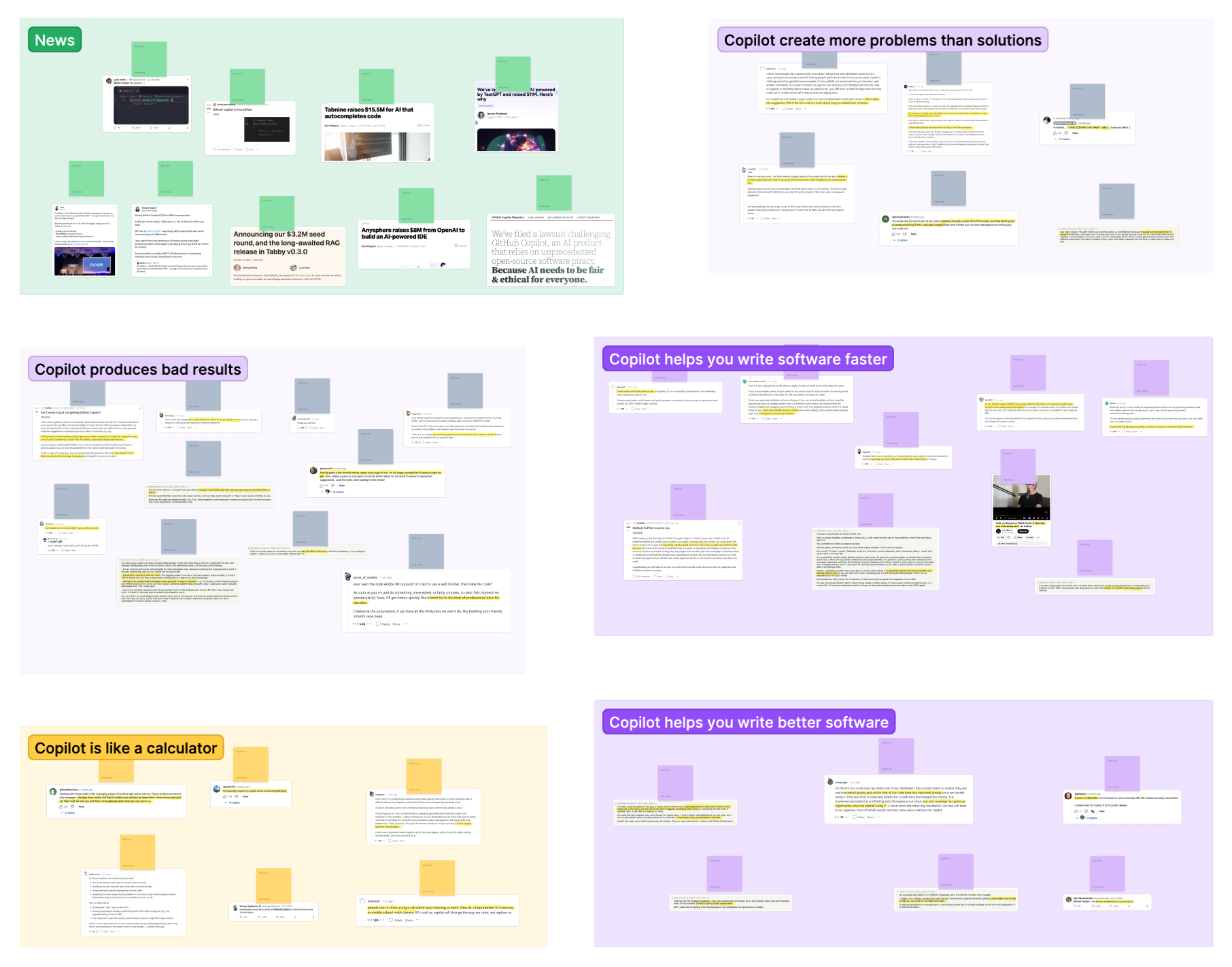
Next, I transcribed these discussions onto a whiteboard, organizing them into "Pro-gRPC" (👍), "Anti-gRPC" (👎), or "Neutral" (🧐) categories, and then clustering them into distinct opinions. Each section in this post showcases an opinion while referencing pertinent discussions.

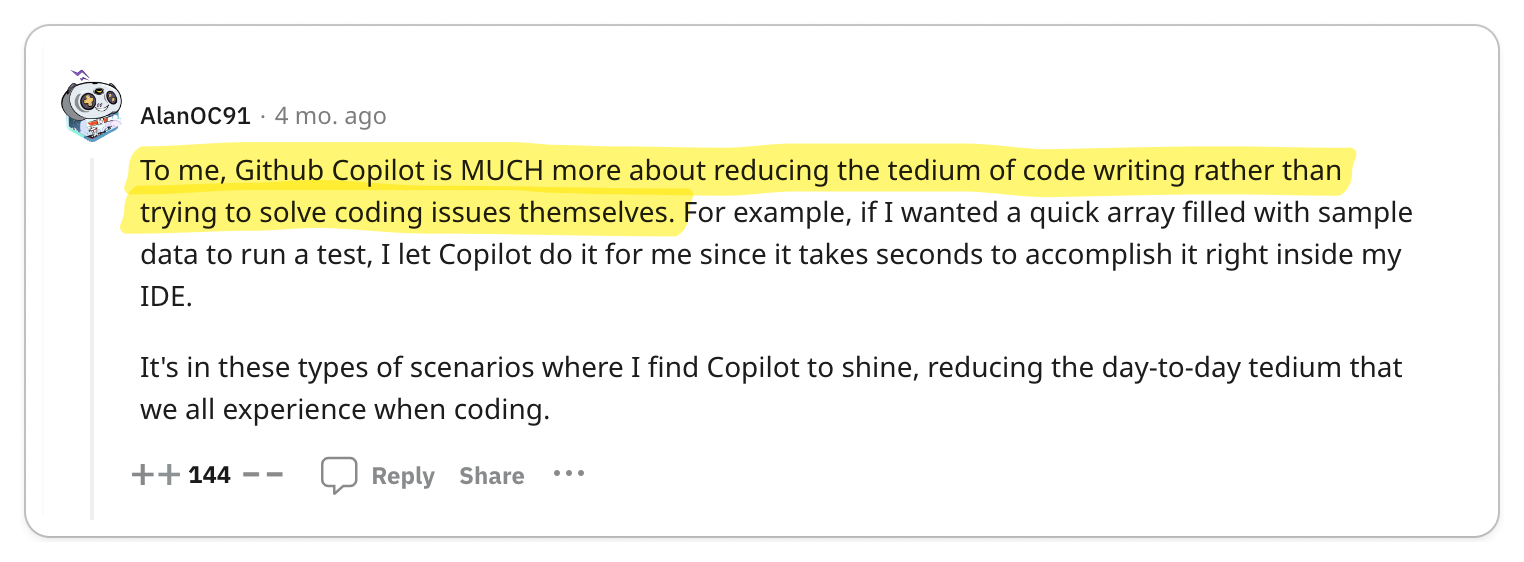
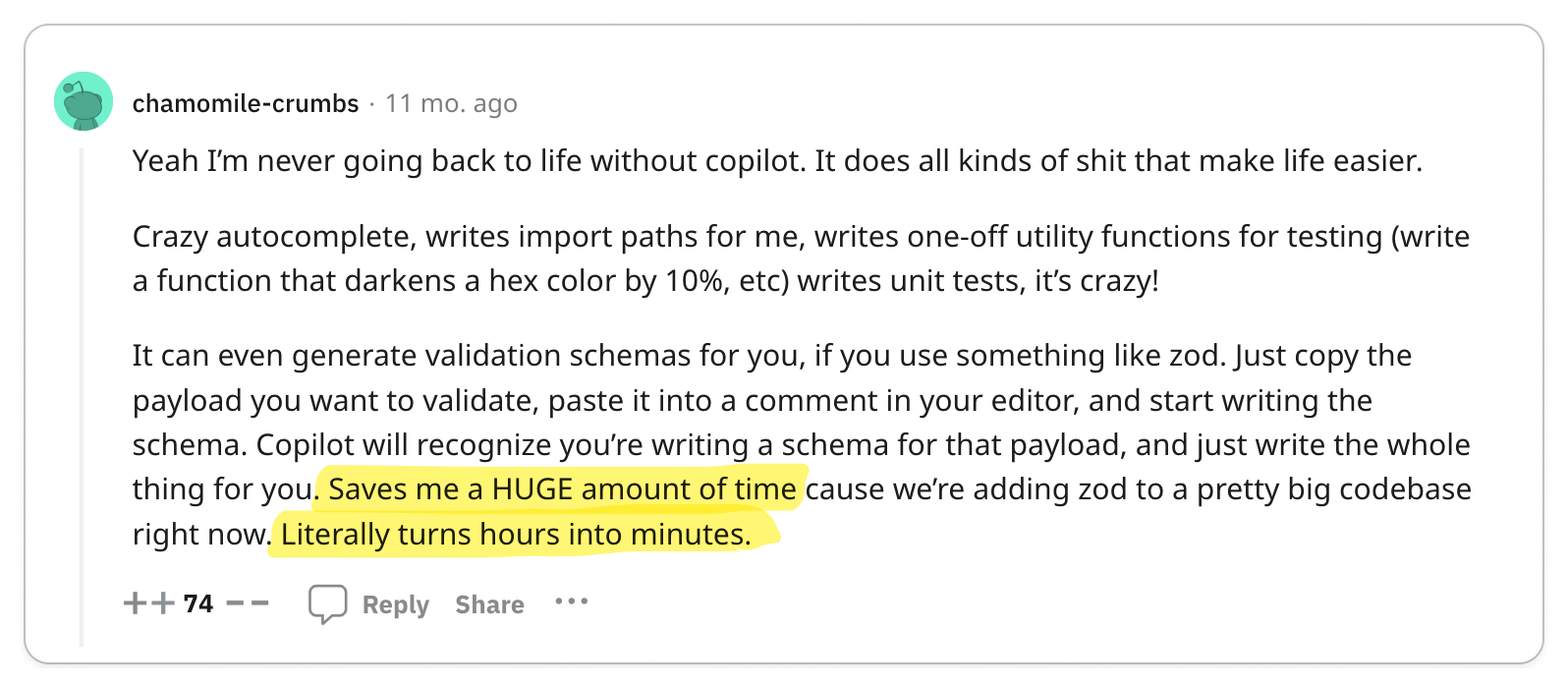
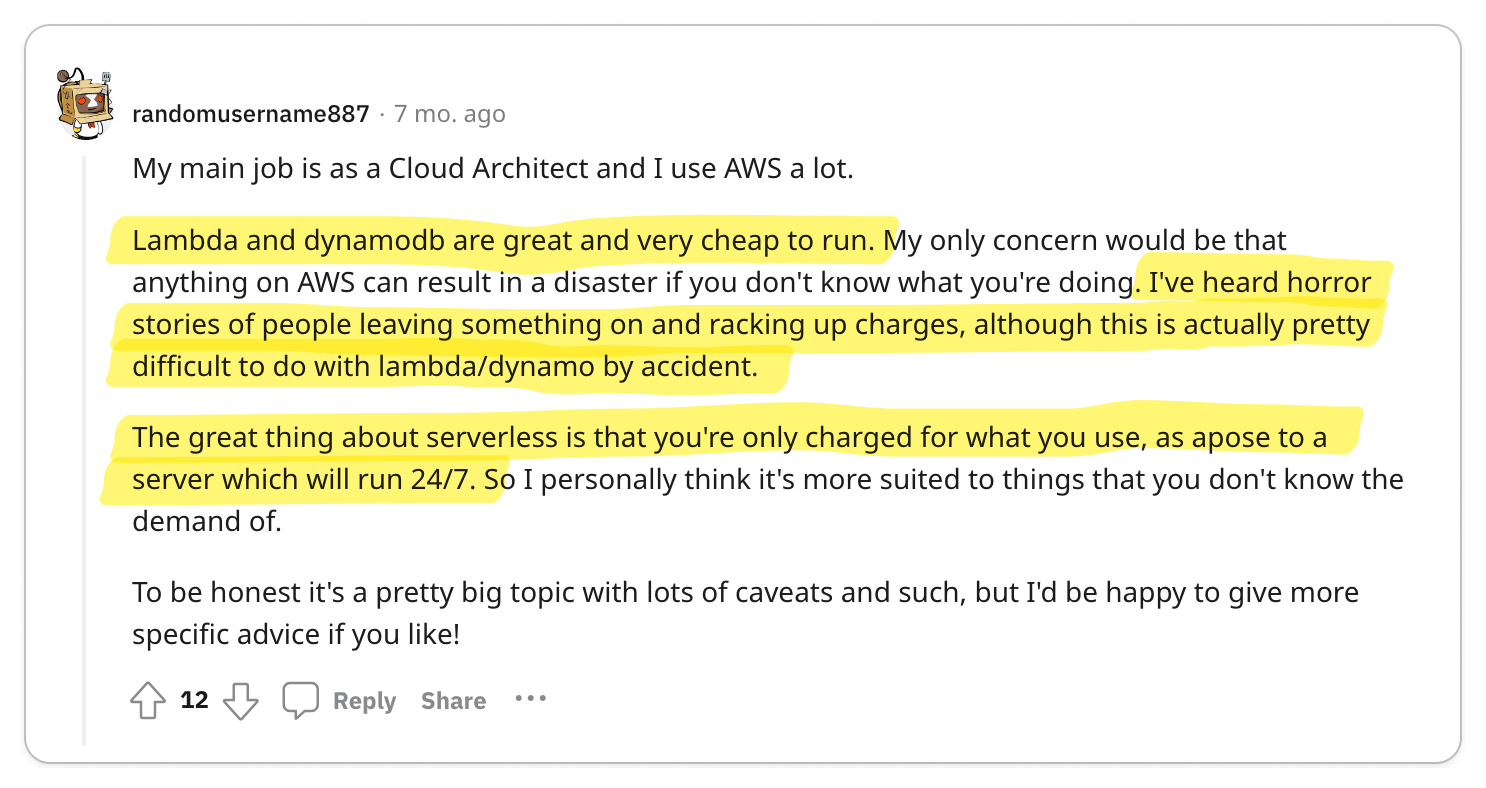
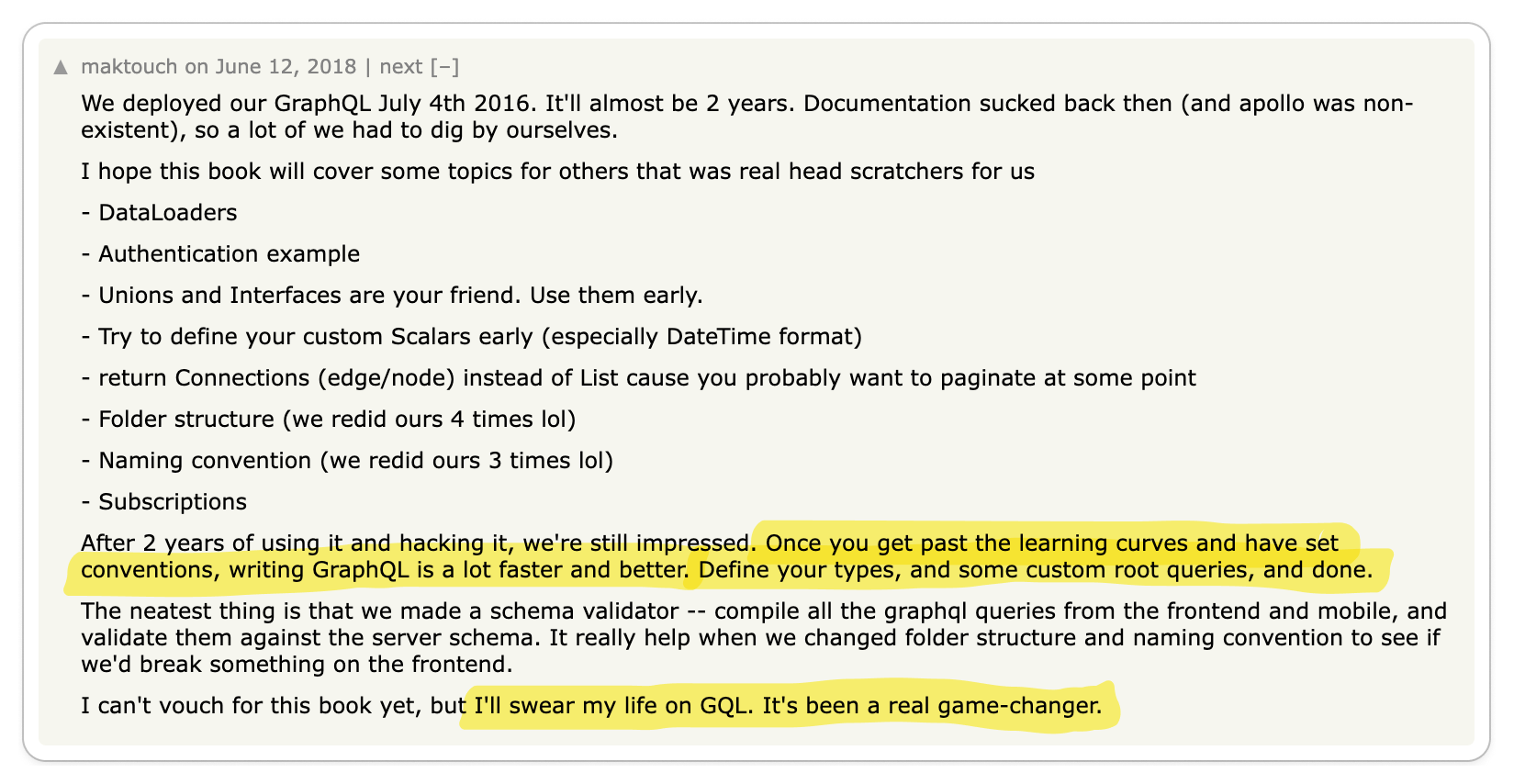
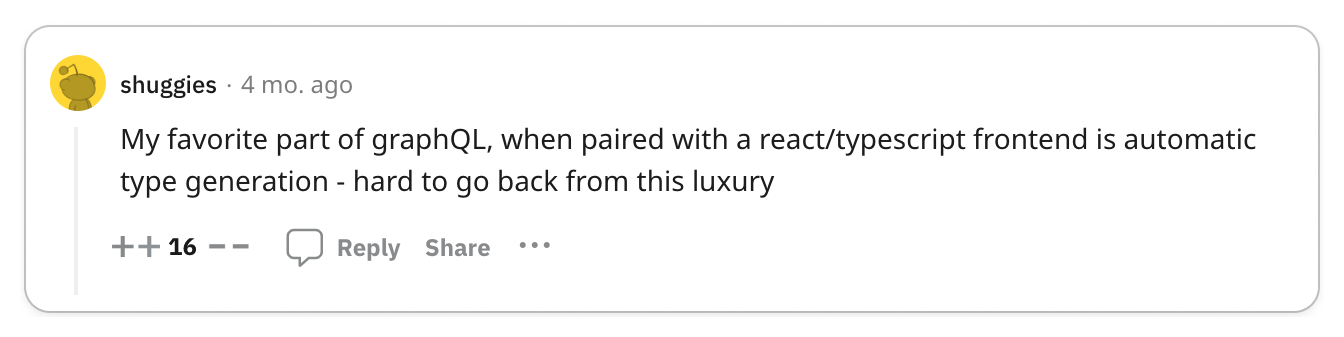
👍 gPRC's Tooling Makes It Great for Service-to-Service Communication
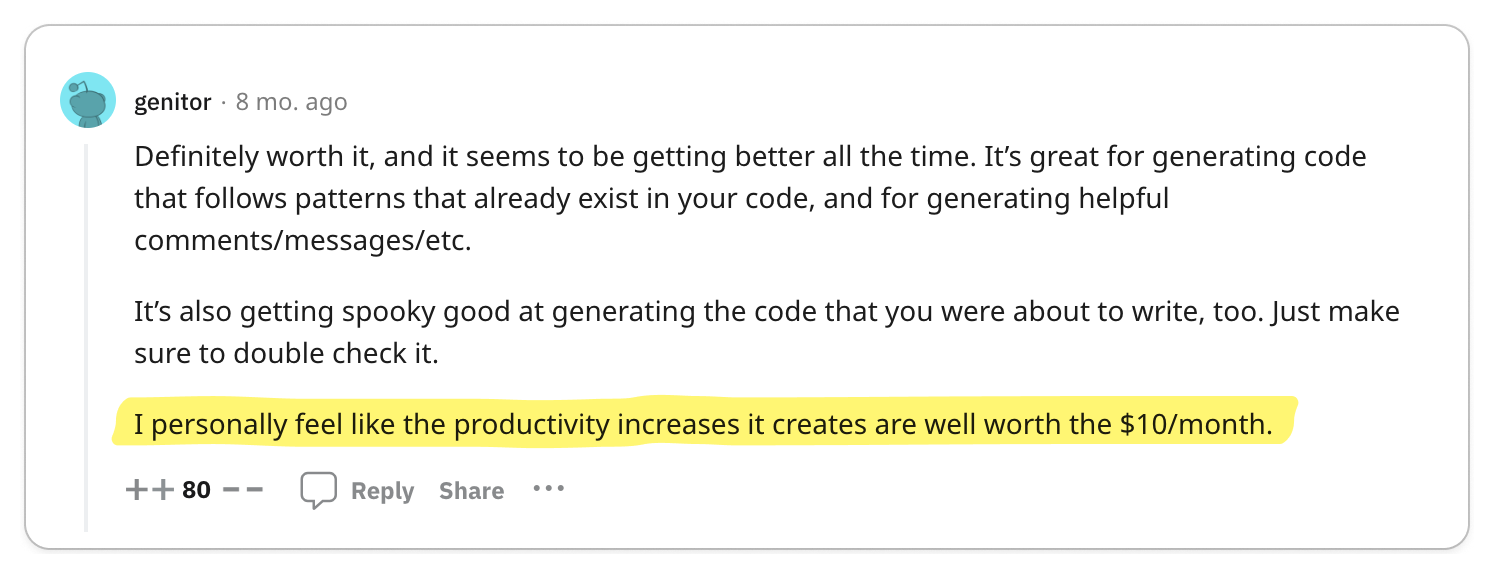
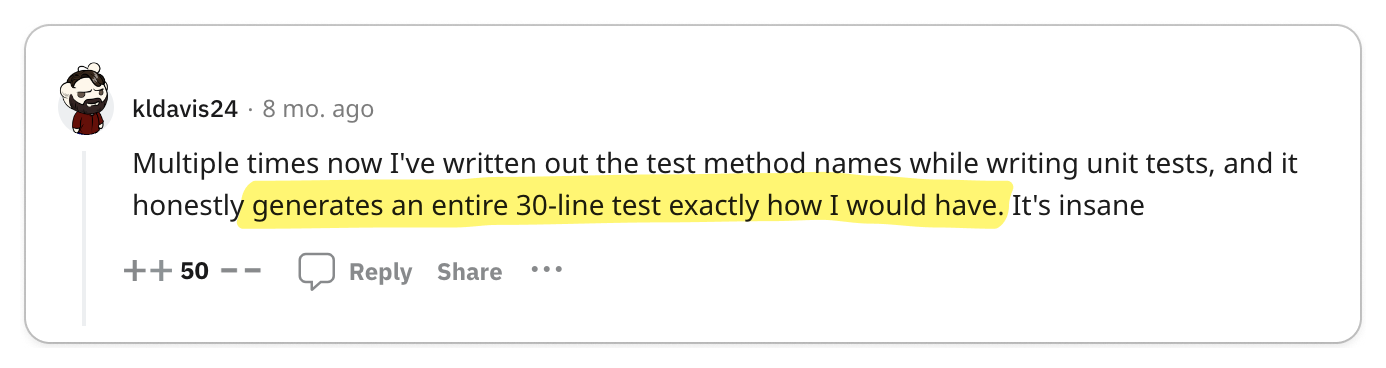
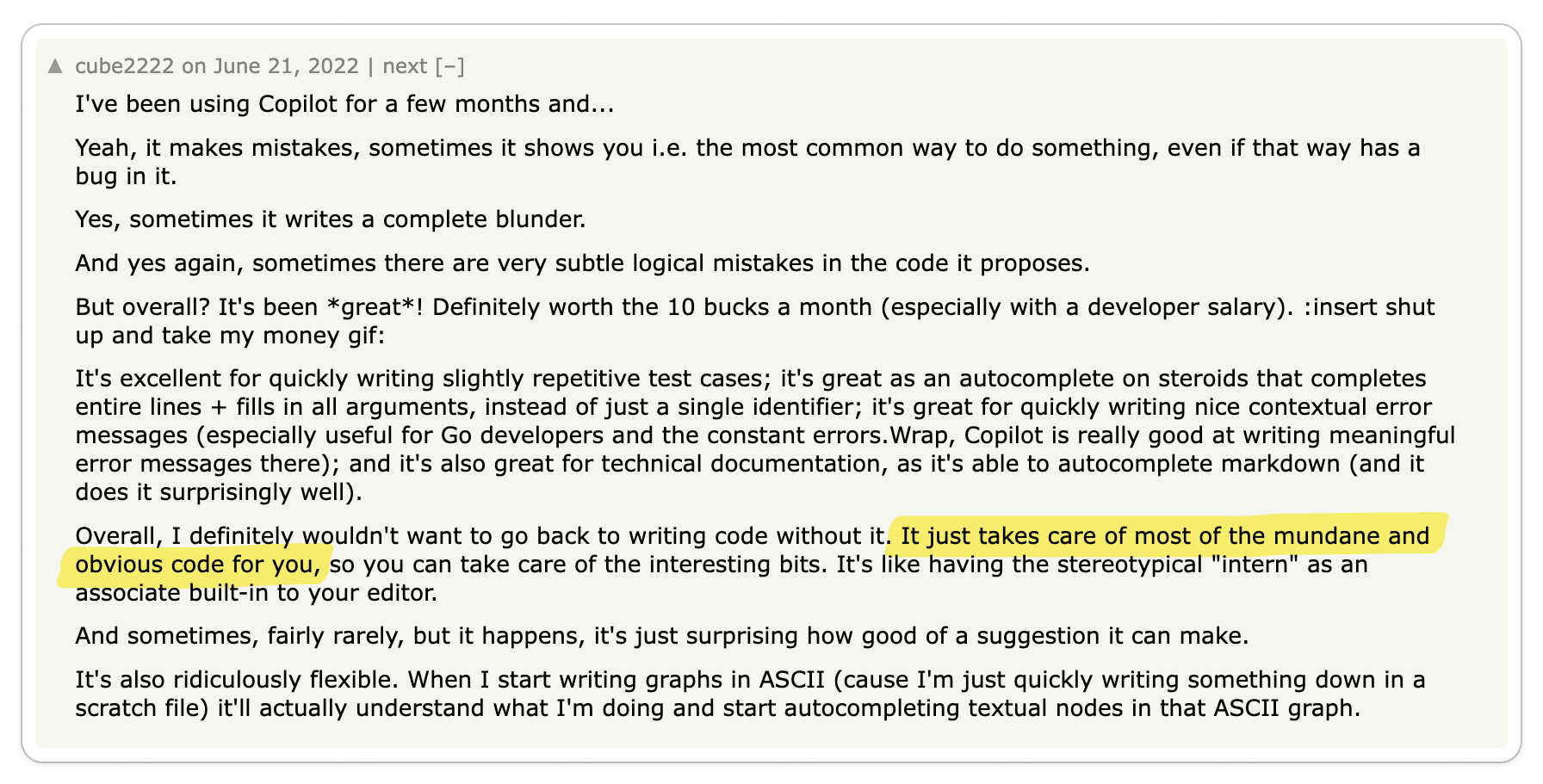
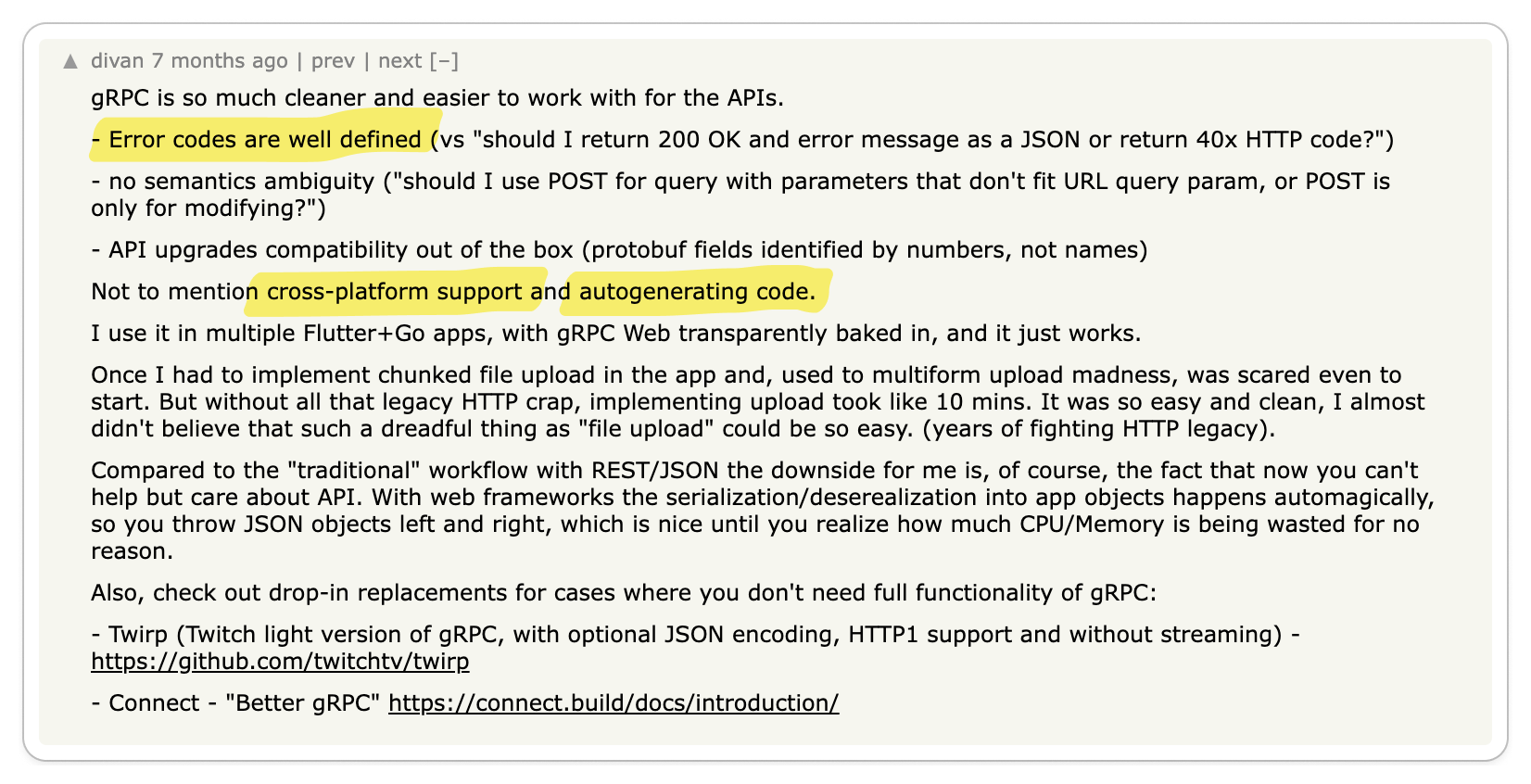
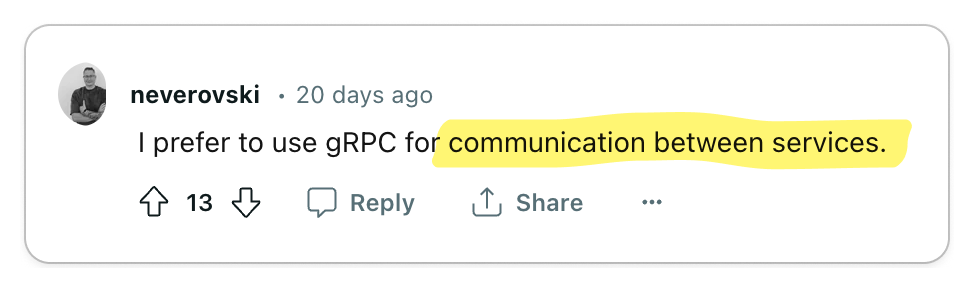
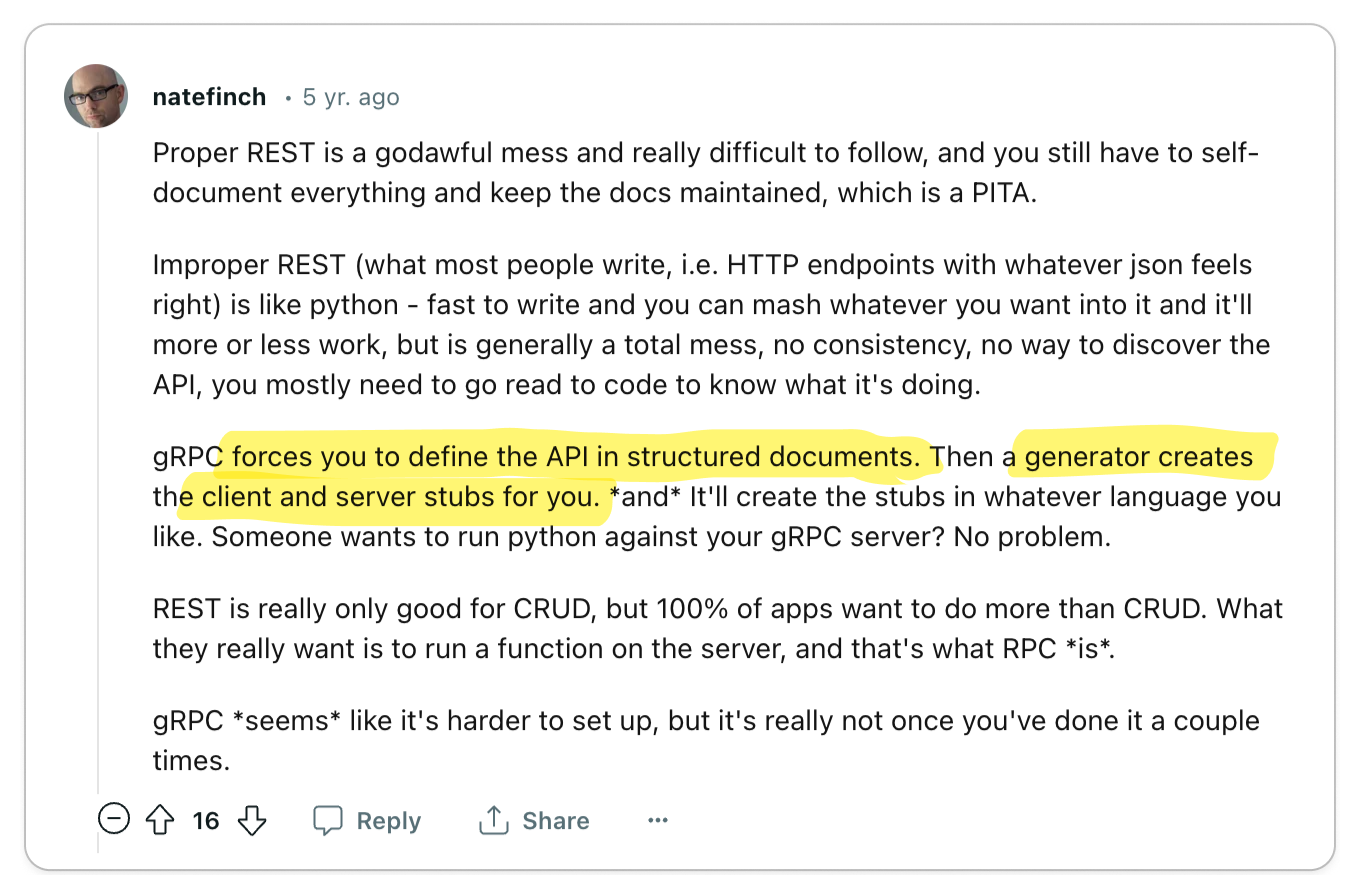
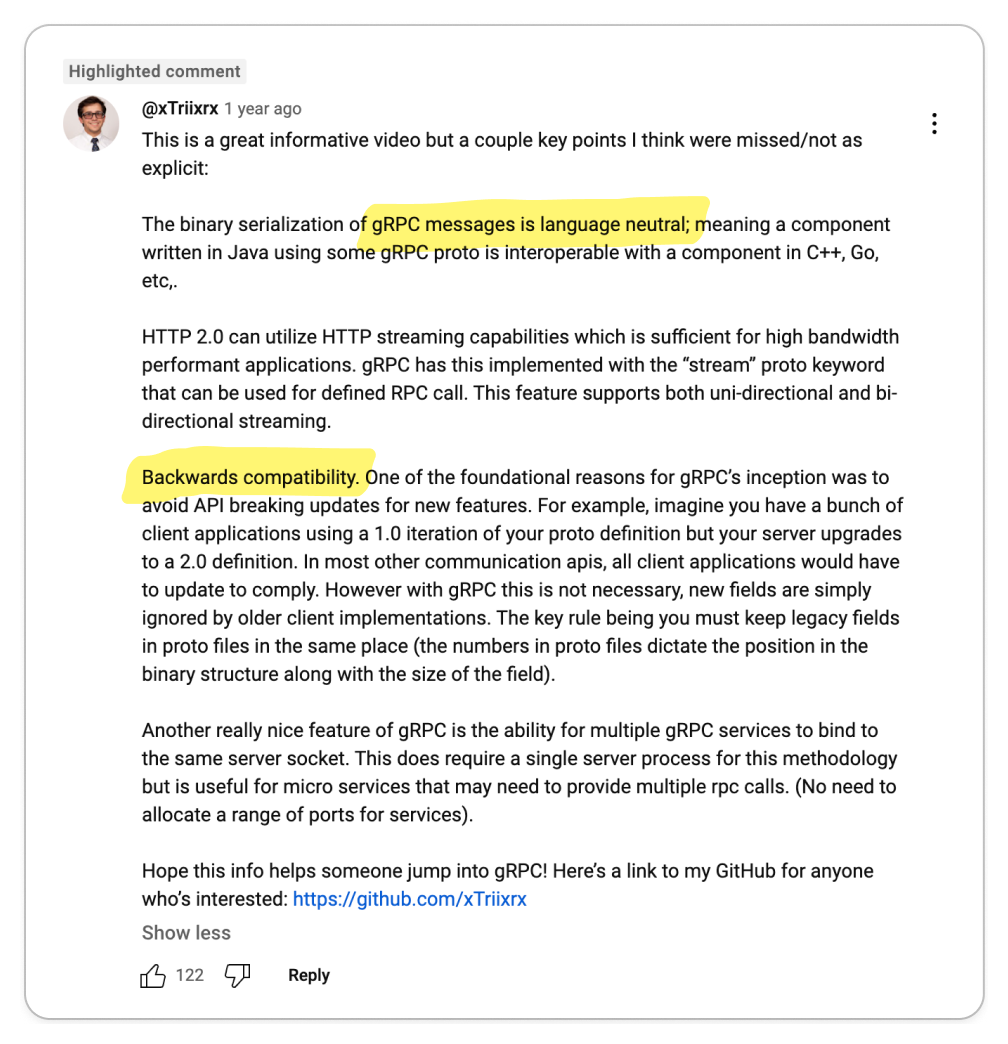
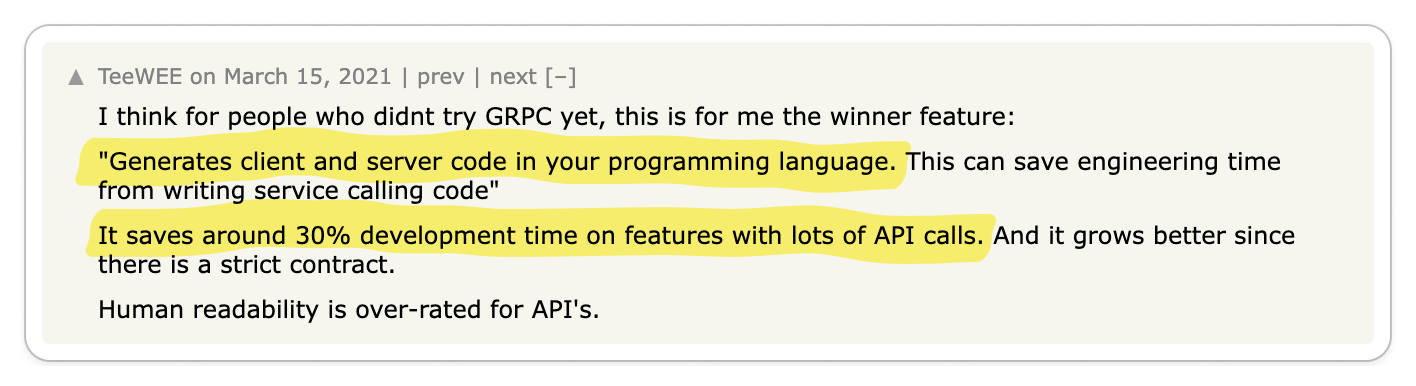
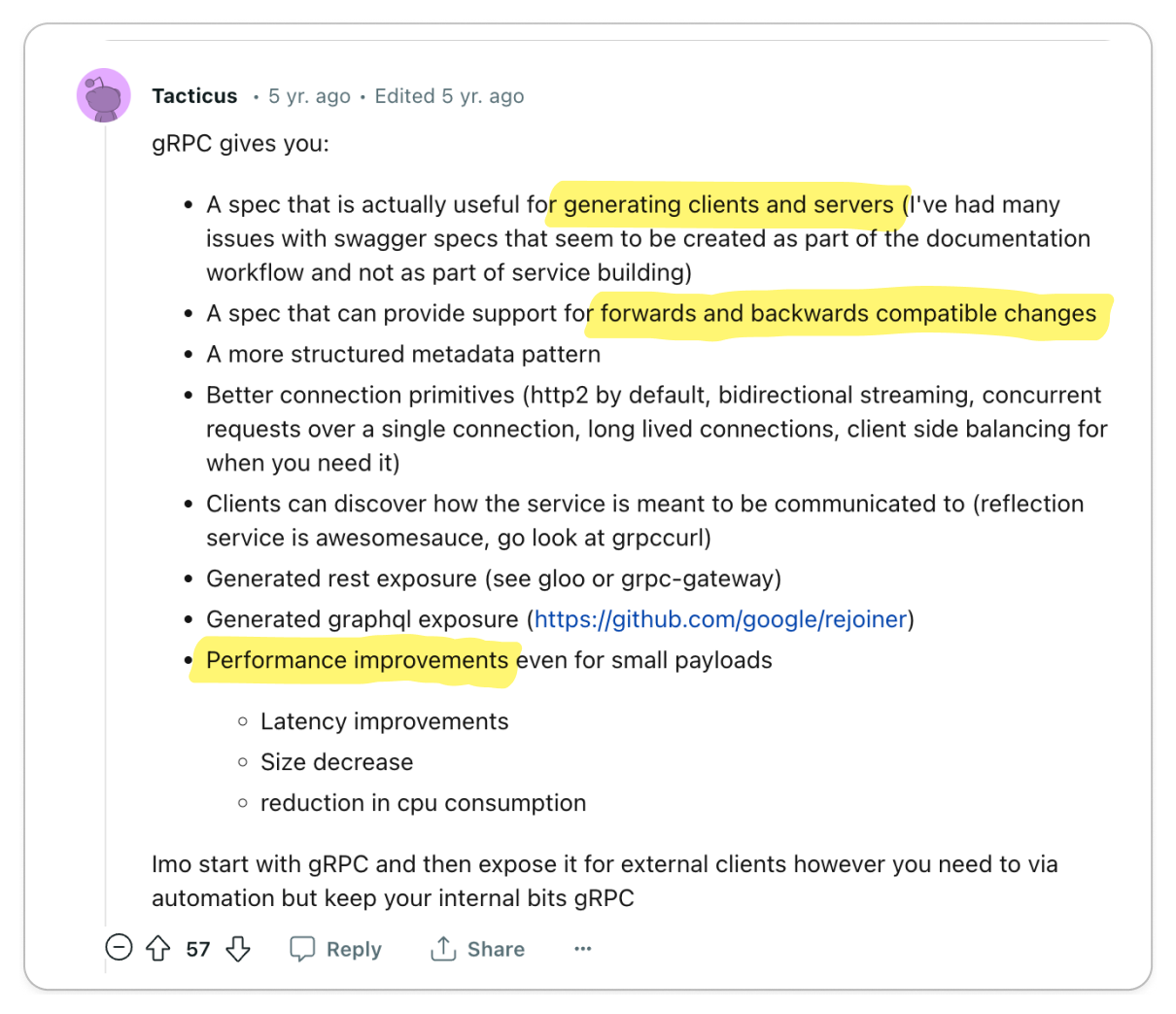
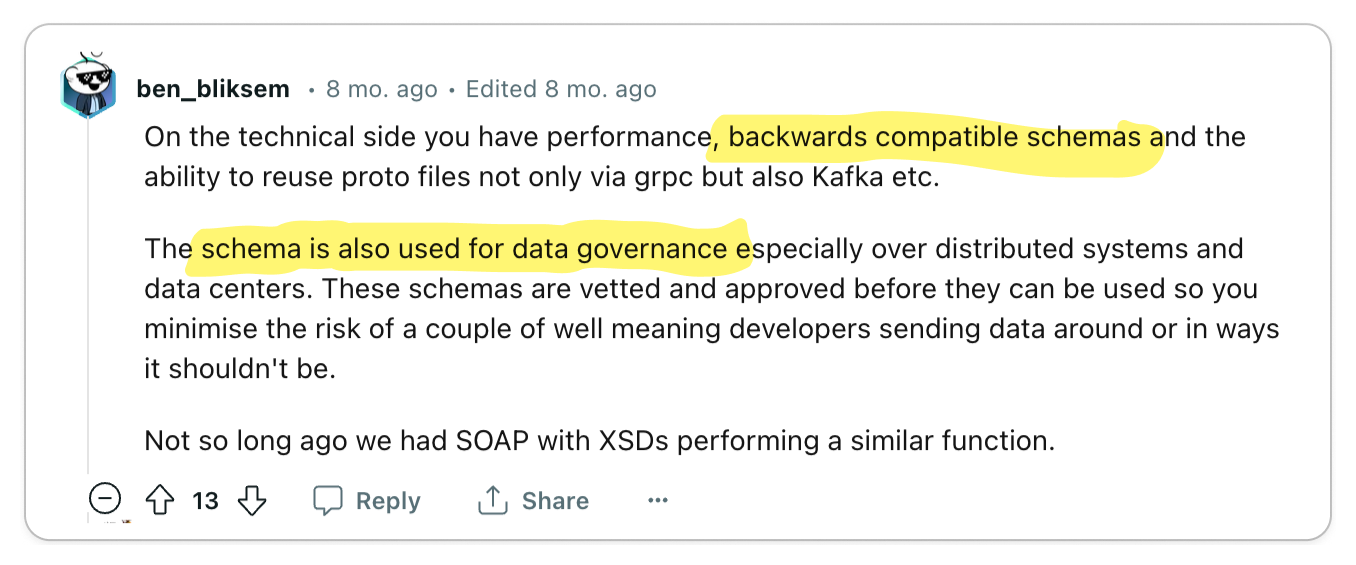
The most significant praise for gRPC centers on its exceptional code generation tools and efficient data exchange format, which together enhance service-to-service developer experience and performance remarkably.


Key Takeaway 🔑
Engineering teams are often responsible for managing multiple services while also interacting with services managed by other teams. Code generation tools empower developers to expedite their development process and create more reliable services. The adoption of Protocol Buffers encourages engineers to focus primarily on the interfaces and data models they expose to other teams, promoting a uniform workflow across various groups.
The key benefits of gRPC mentioned were:
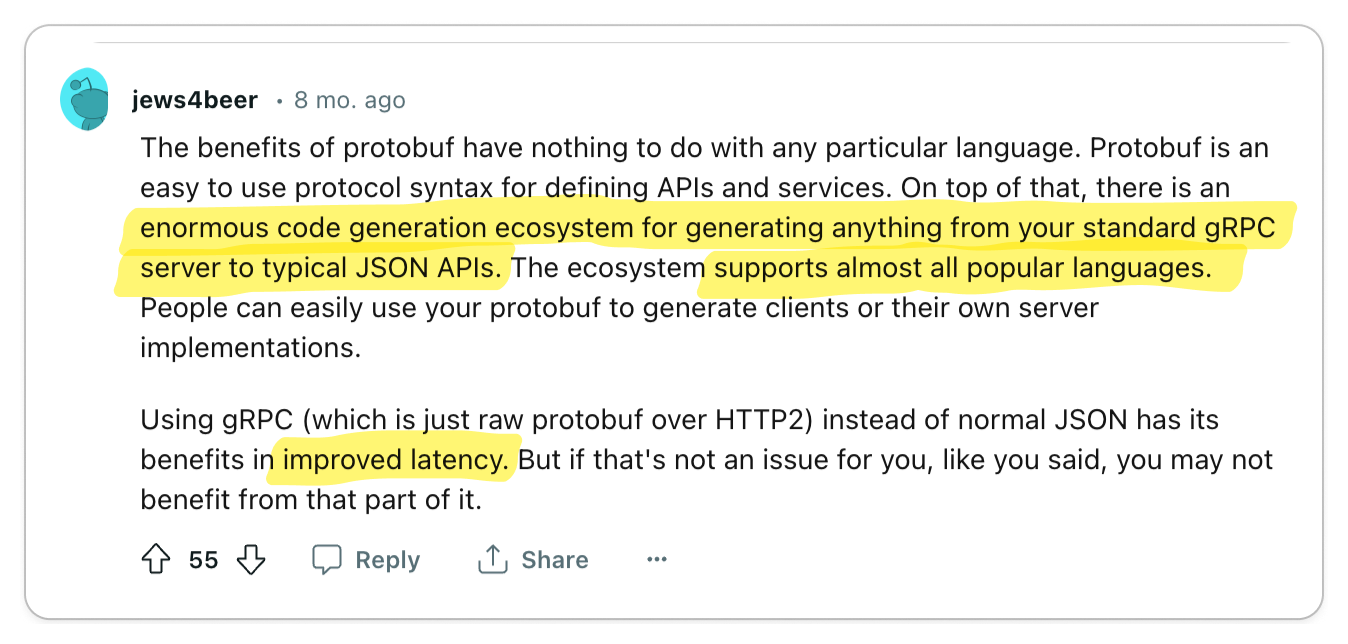
- Client and server stub code generation tooling
- Data governance
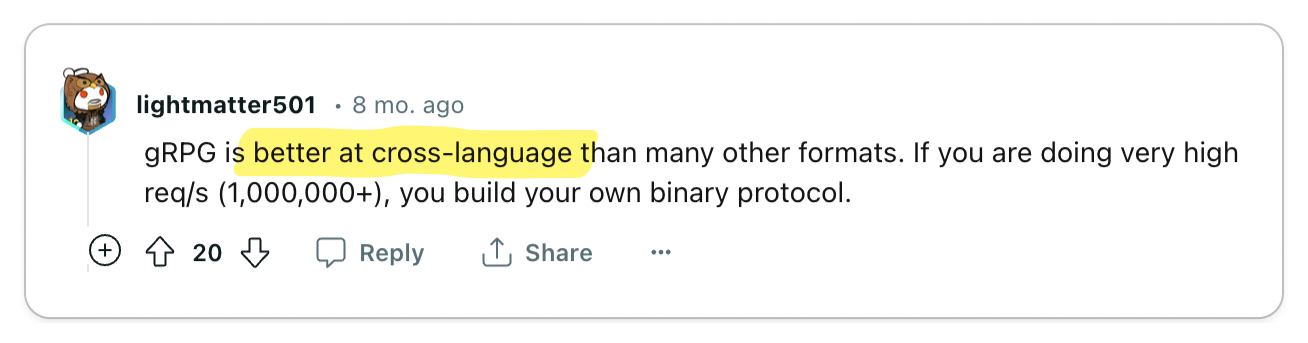
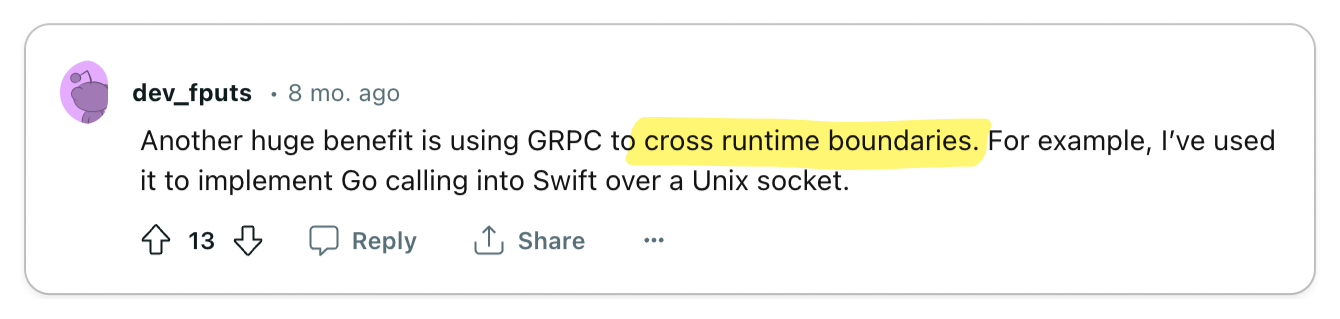
- Language-agnostic architecture
- Runtime Performance
- Well-defined error codes
If your organization is developing a multitude of internal microservices, gRPC could be an excellent option to consider.
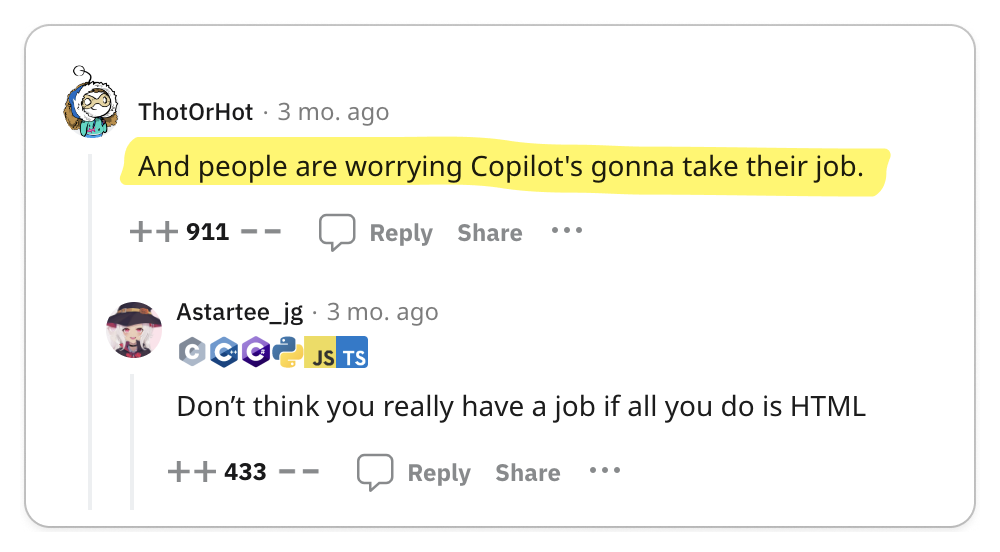
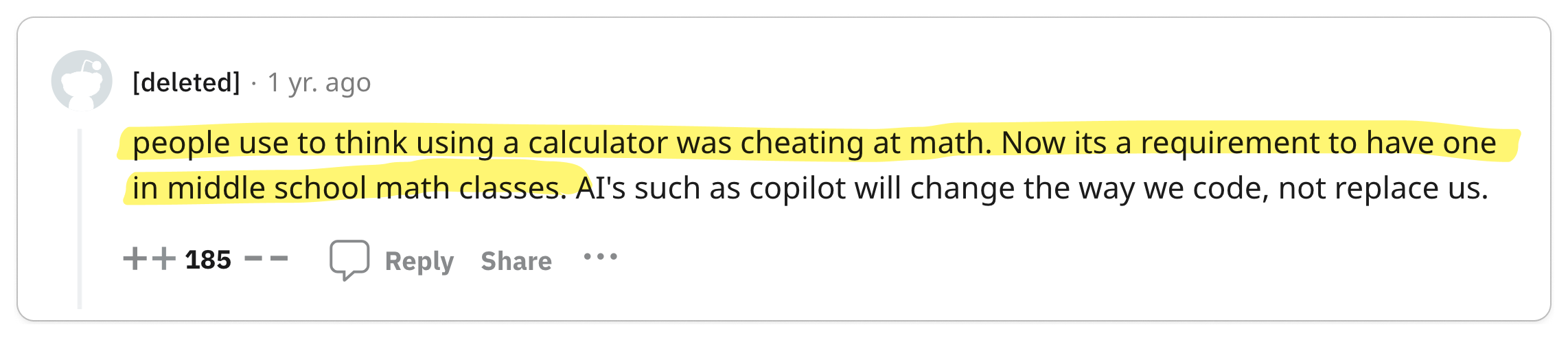
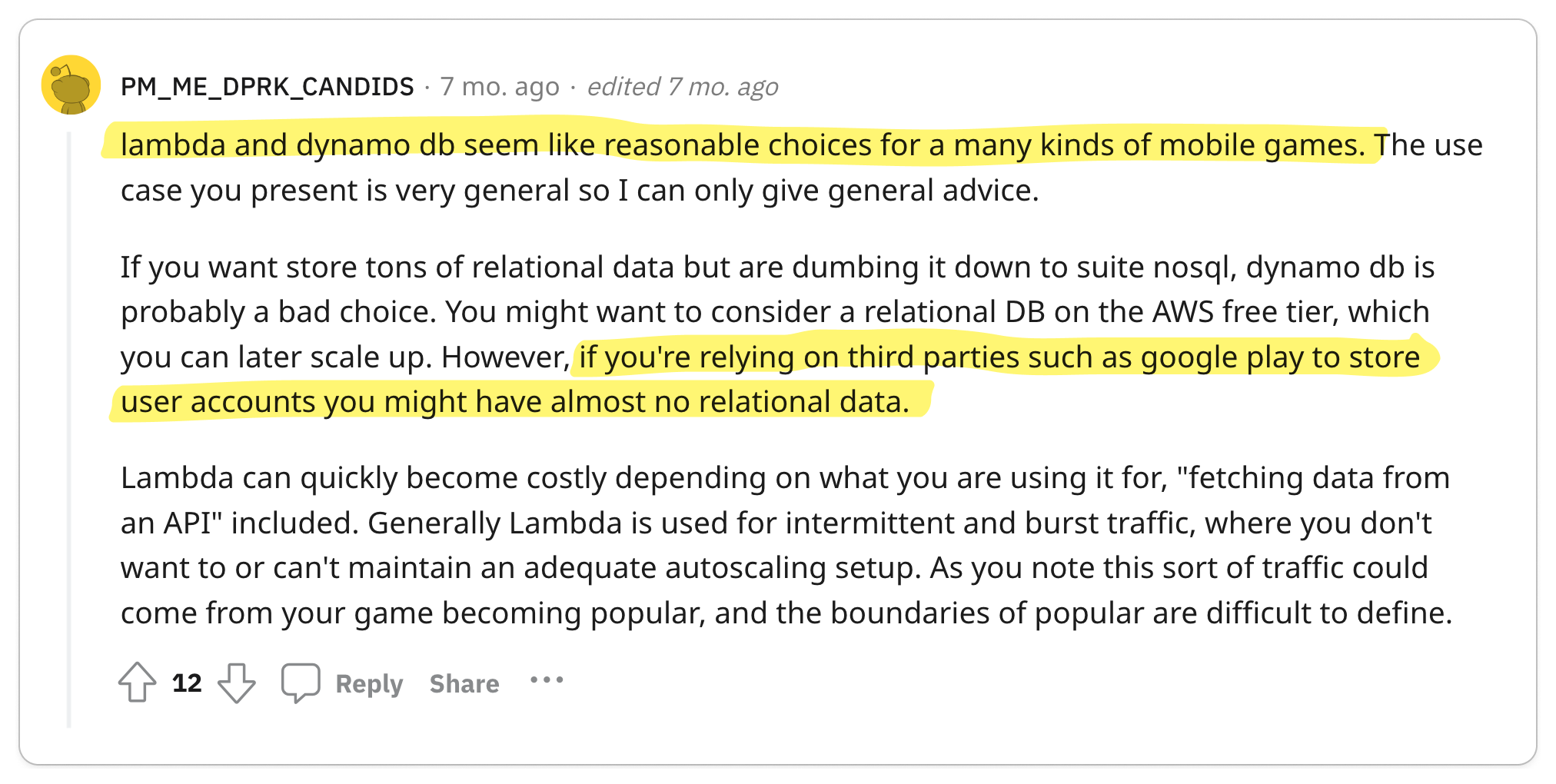
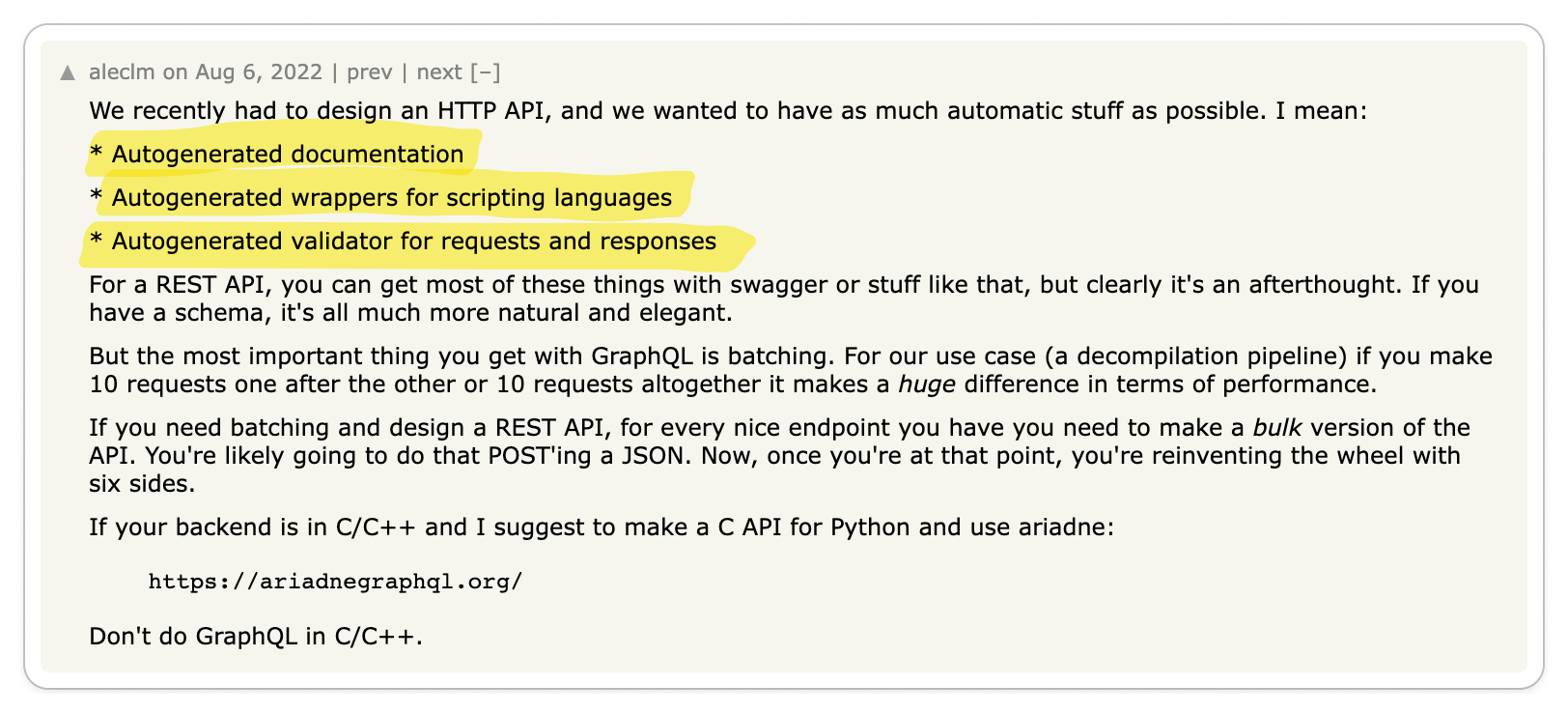
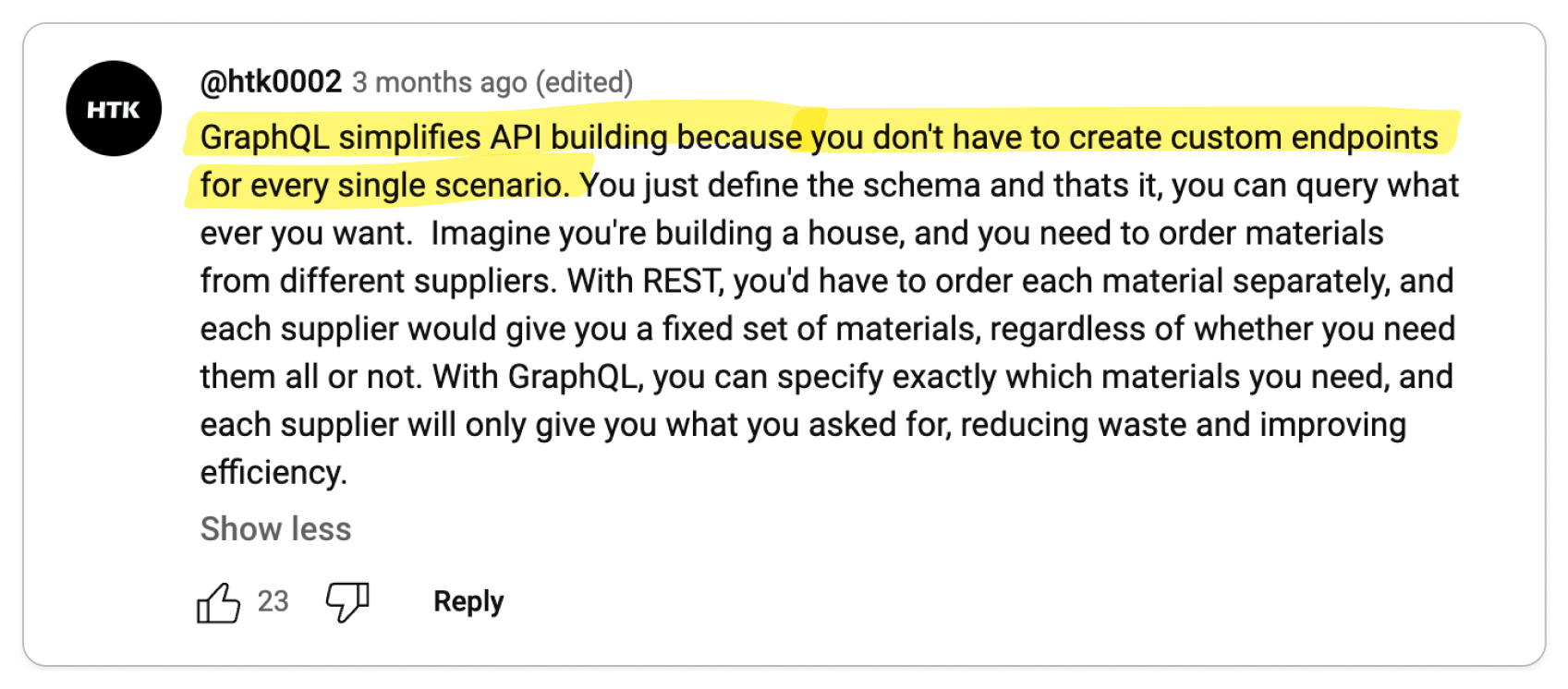
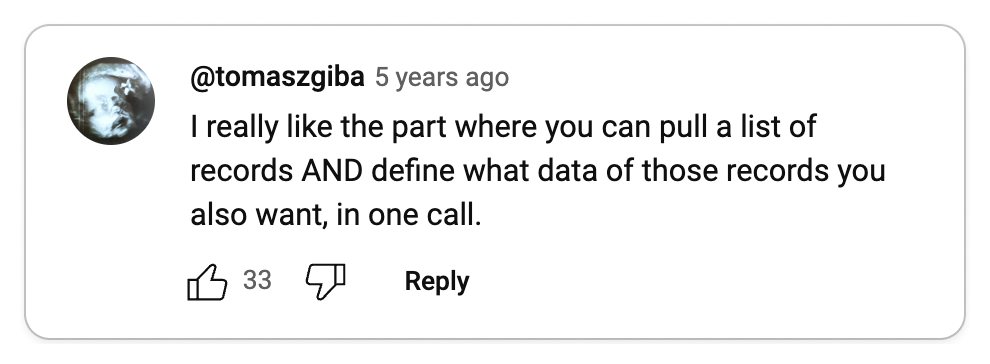
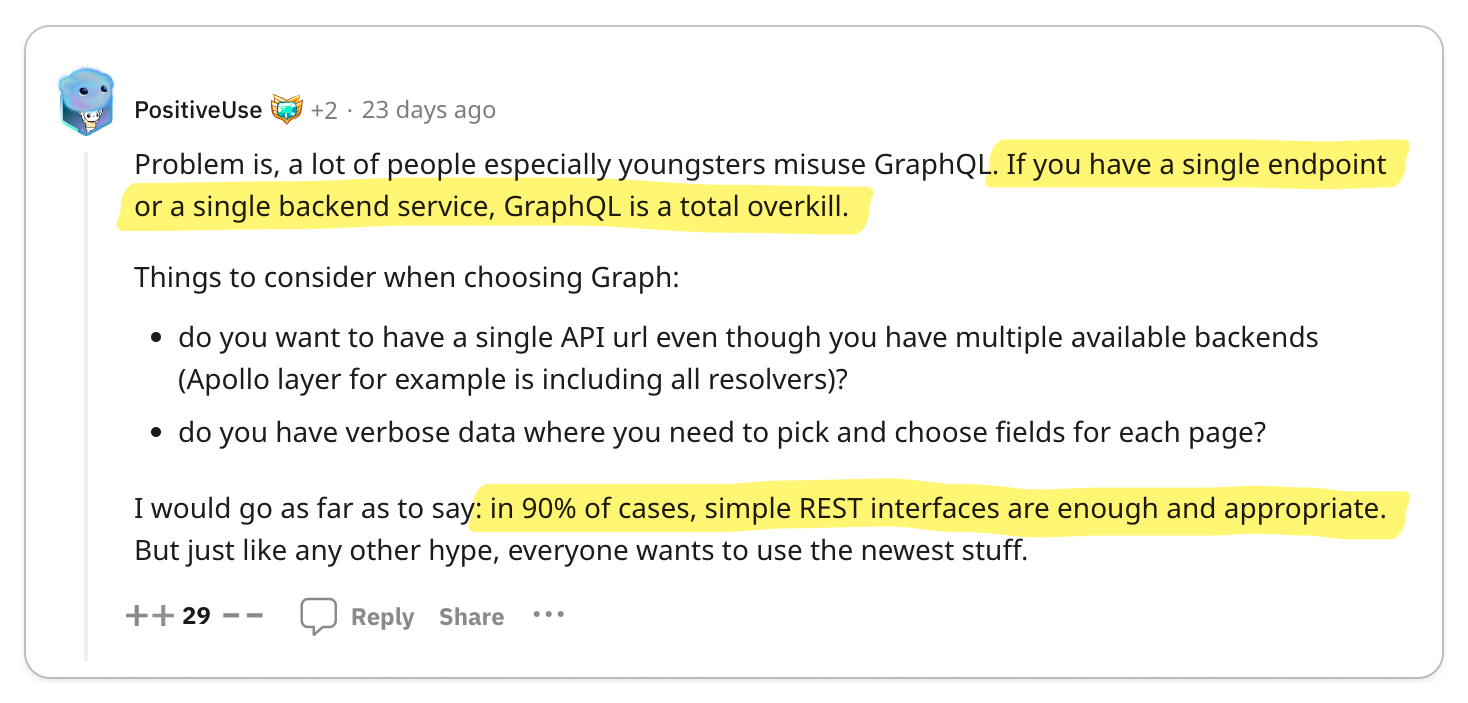
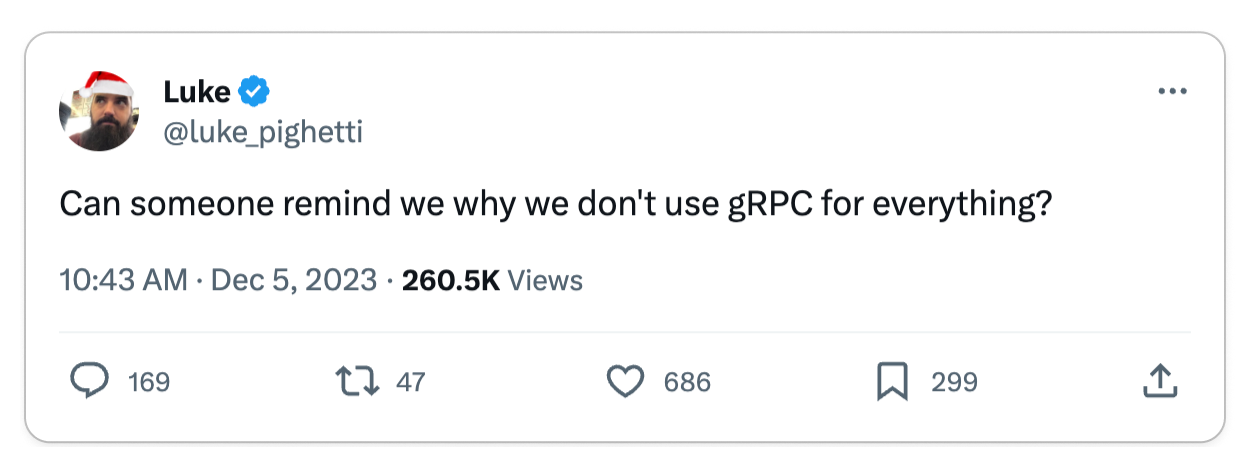
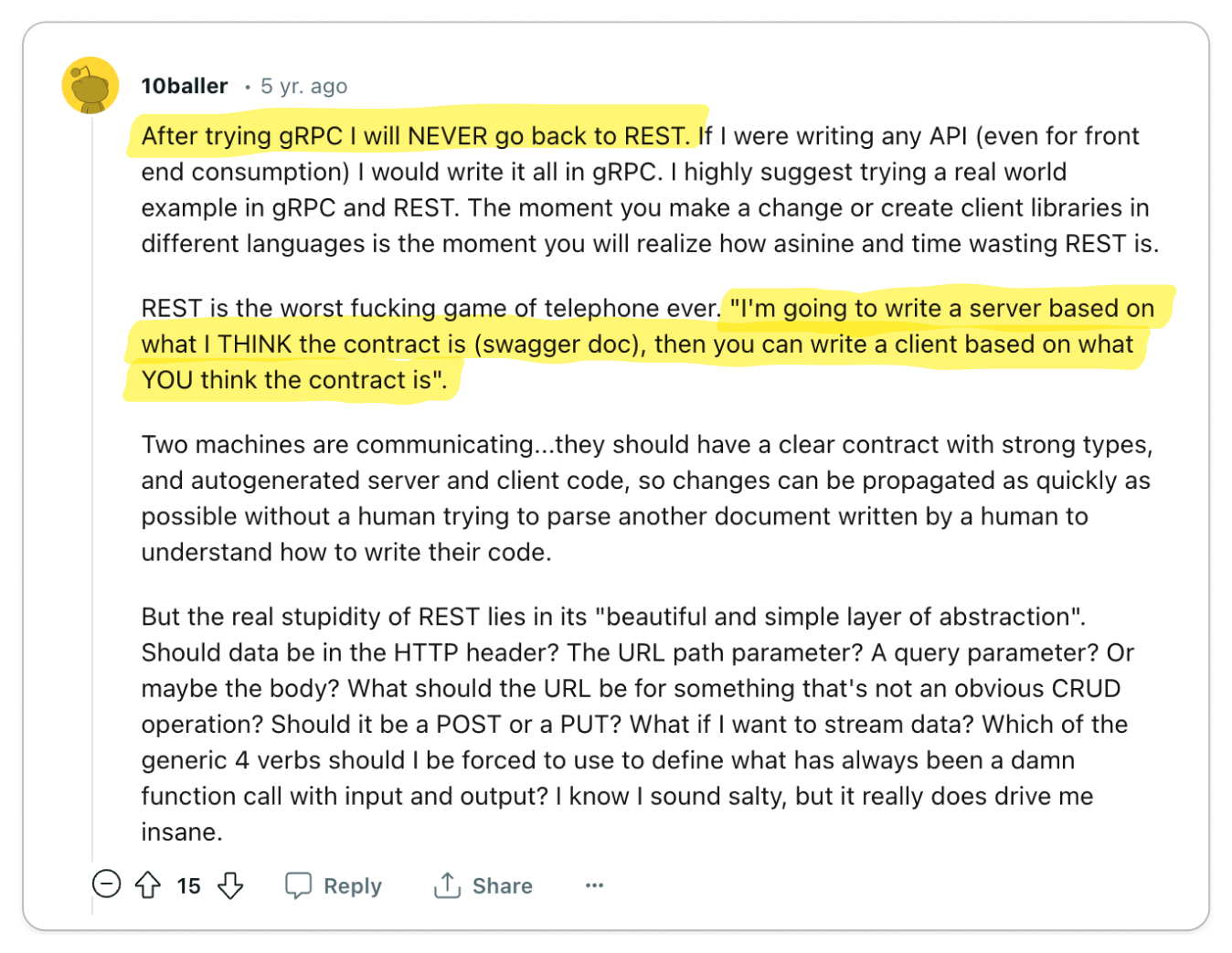
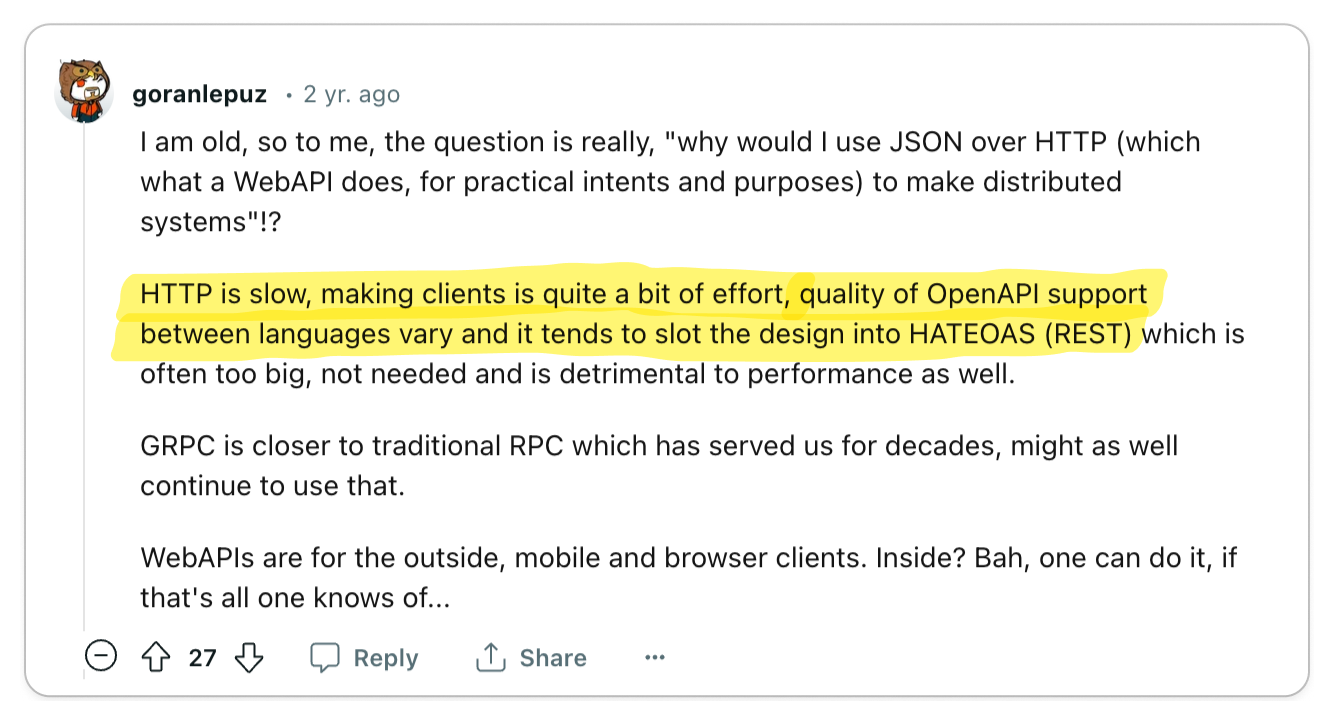
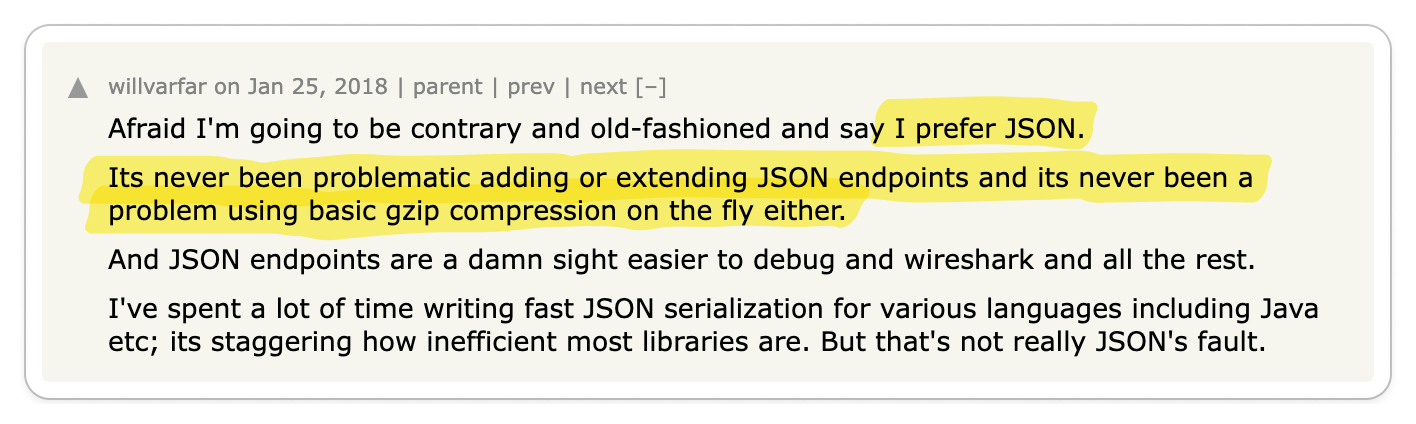
👍 Compared to the straightforward nature of gRPC, REST can be relatively confusing
To properly build applications in REST, you need to understand the underlying protocol, HTTP. gRPC, on the other hand, abstracts HTTP away, making it less confusing for quickly building applications.

Key Takeaway 🔑
REST often leaves considerable scope for errors and confusion in defining and consuming APIs.
In contrast, gRPC is designed with the complexities of large-scale software systems in mind. This focus has led to an emphasis on robust code generation and stringent data governance. REST, on the other hand, is fundamentally a software architectural style oriented towards web services, where aspects like code generation and data governance were not primary considerations. The most widely used standard for designing REST APIs, OpenAPI (formerly Swagger), is essentially a specification that the underlying protocol does not enforce. This leads to situations where the API consumer might not receive the anticipated data model, resulting in a loosely coupled relationship between the API definition and the underlying protocol. This disconnect can be a significant source of confusion and frustration for developers. Hence, it raises a critical question: why opt for REST when gRPC offers a more cohesive and reliable alternative?
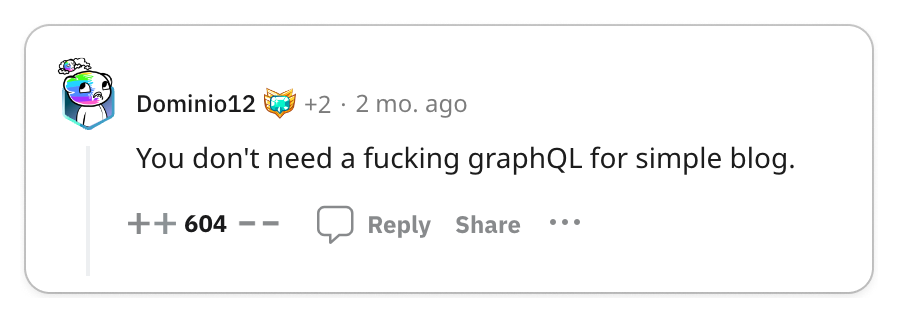
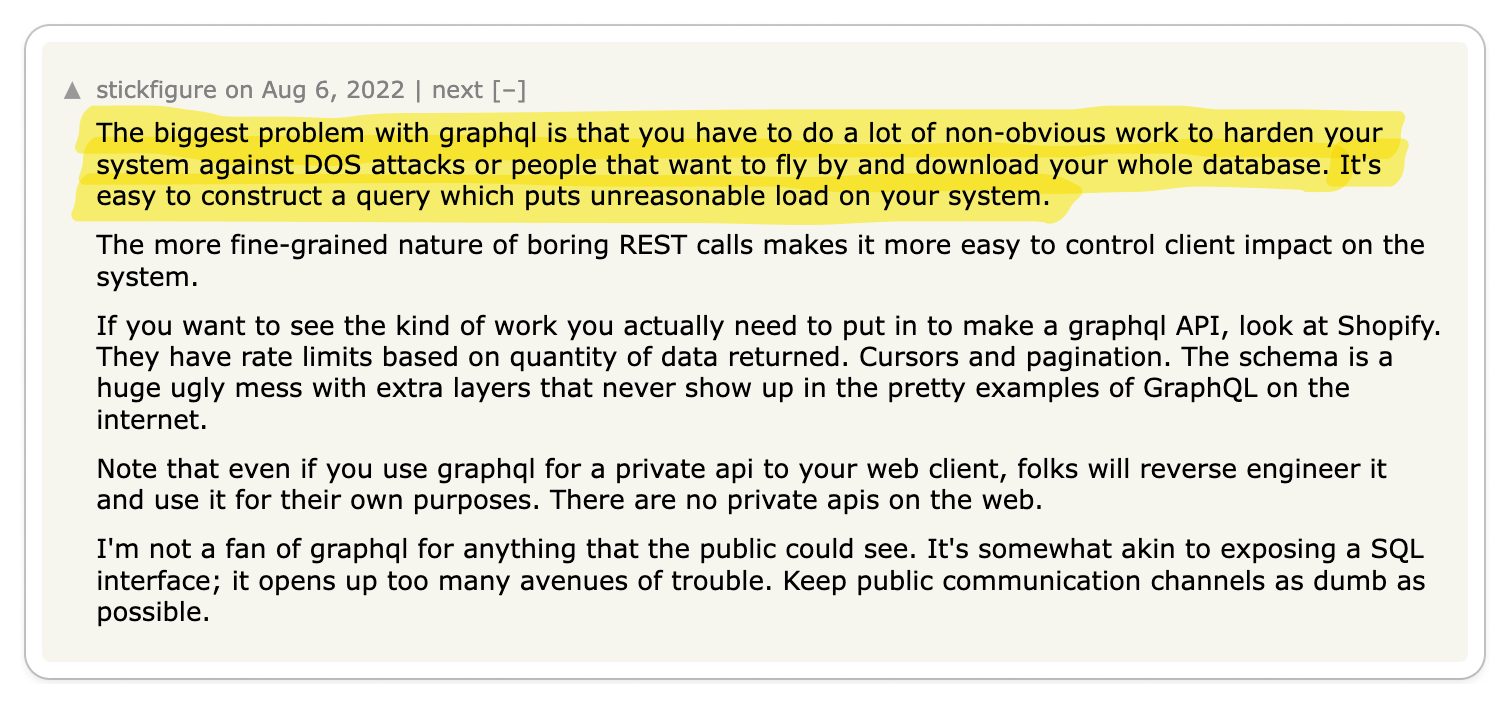
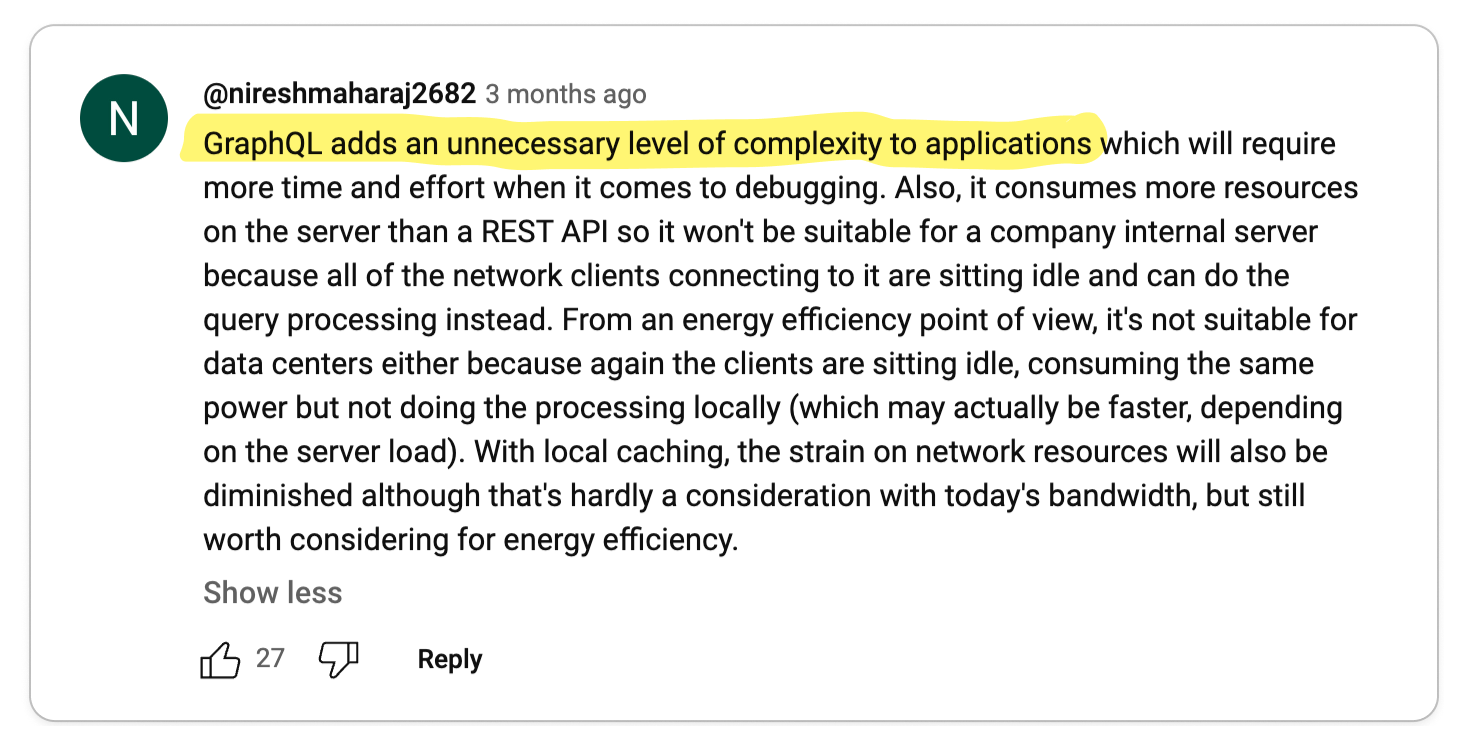
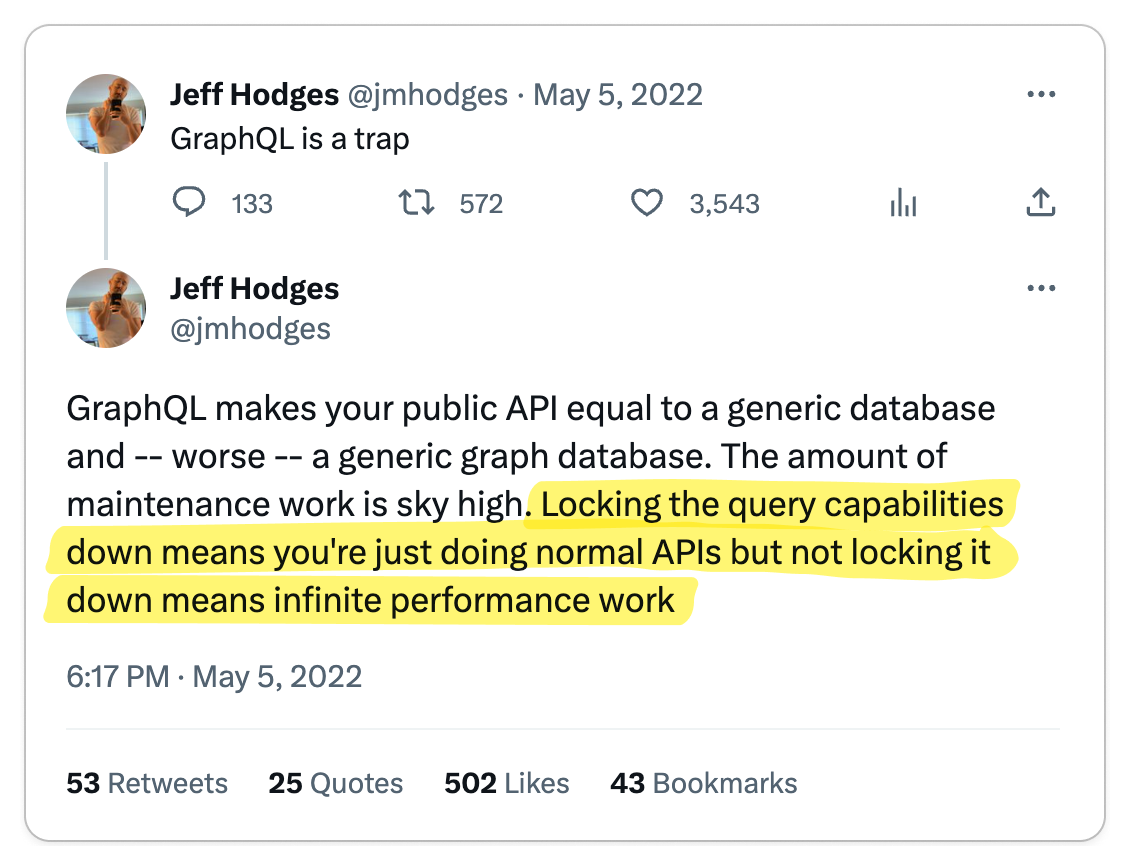
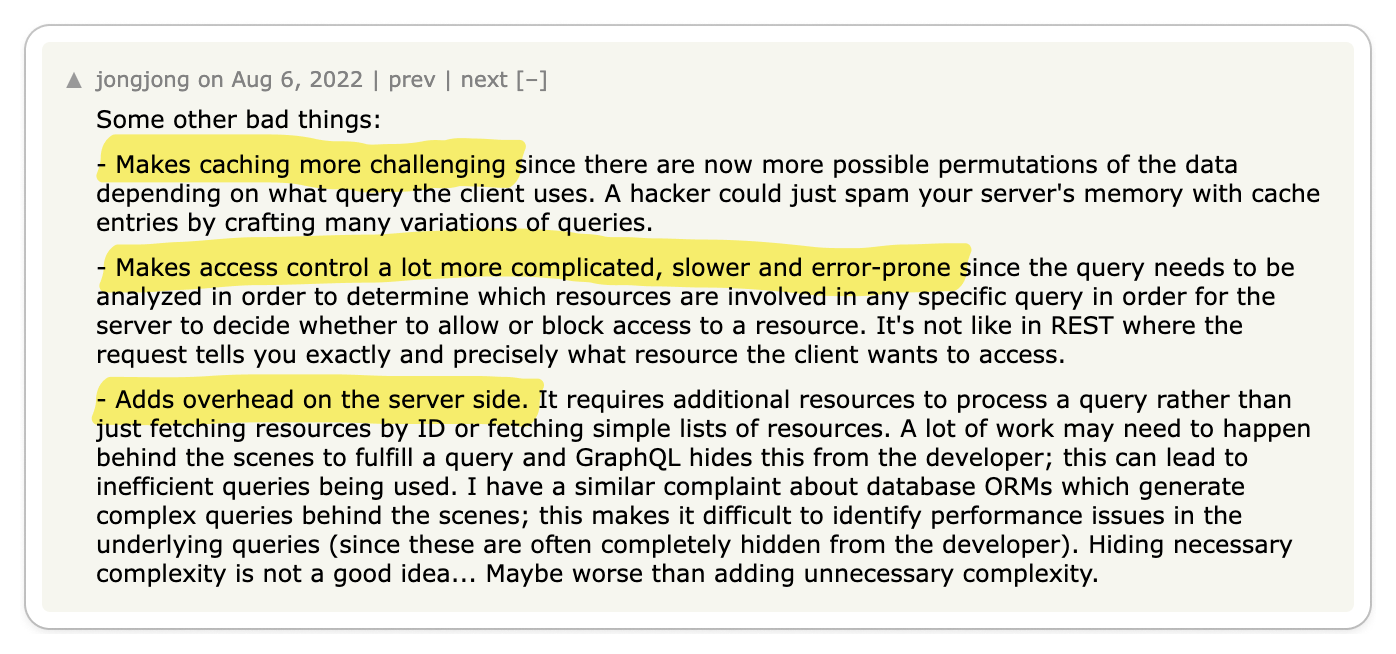
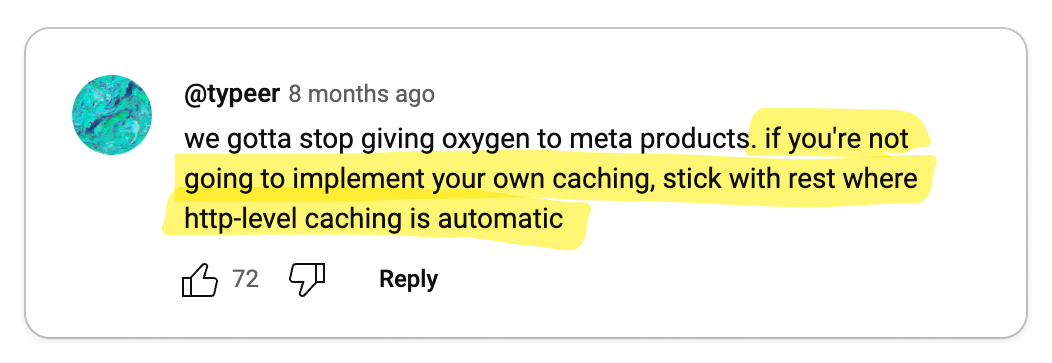
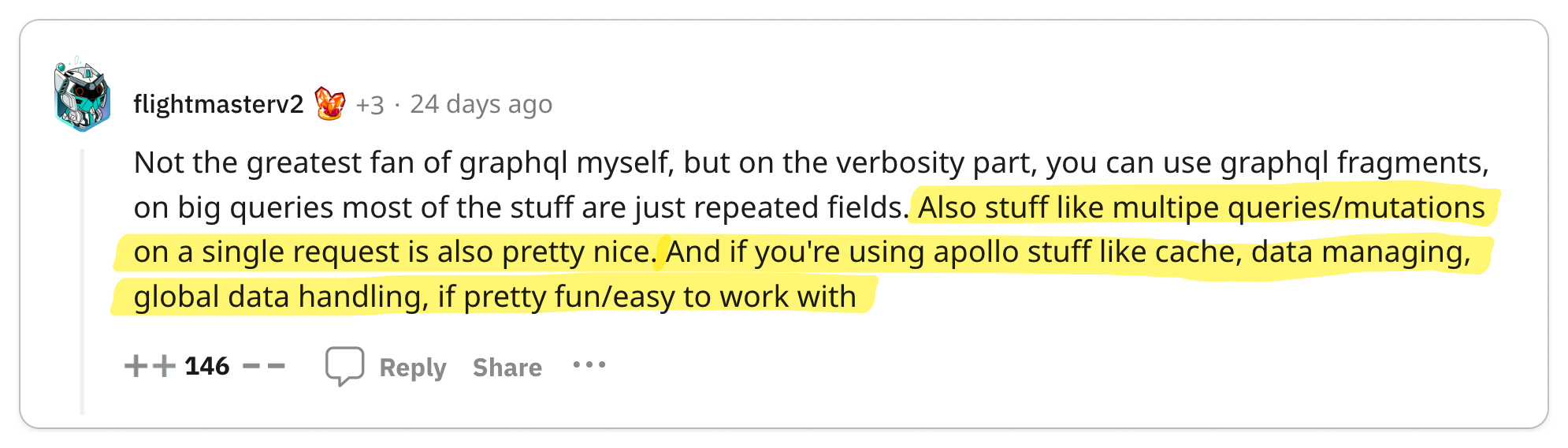
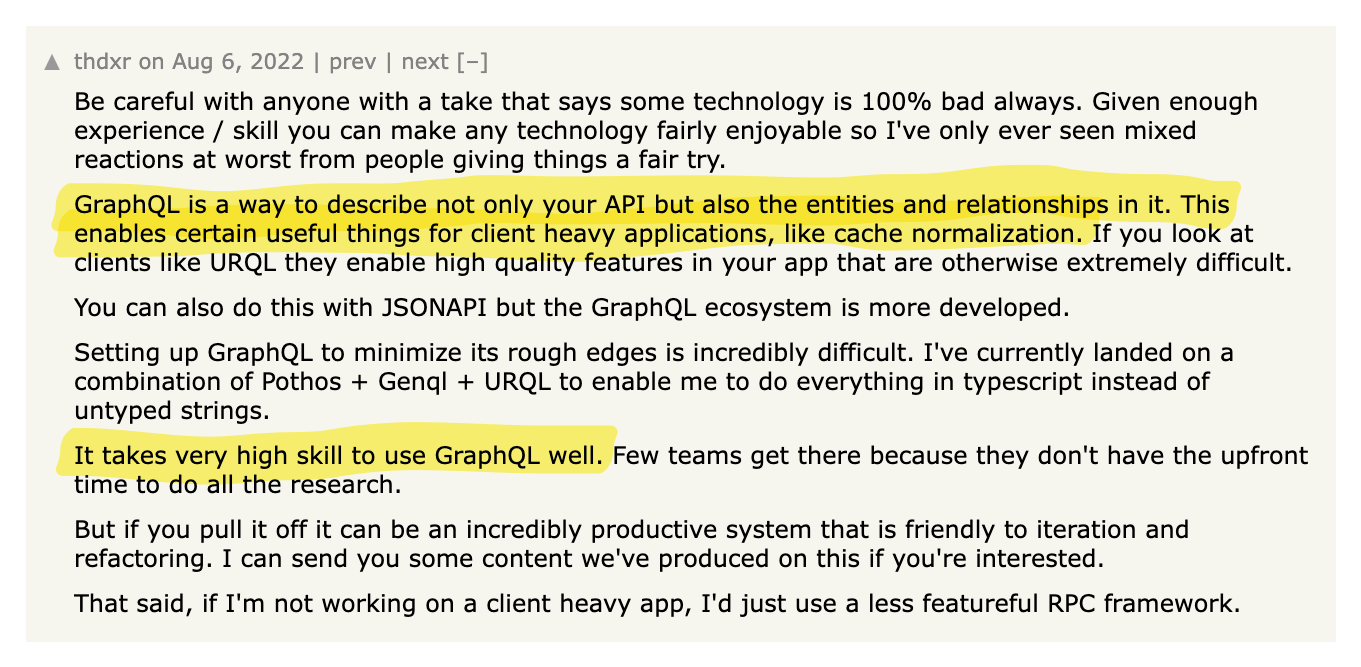
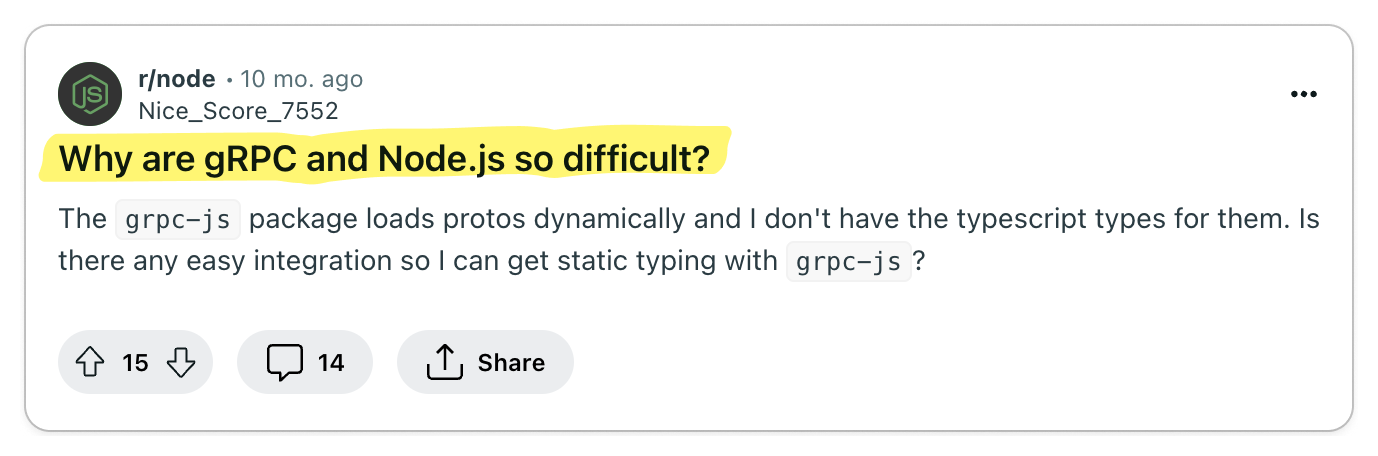
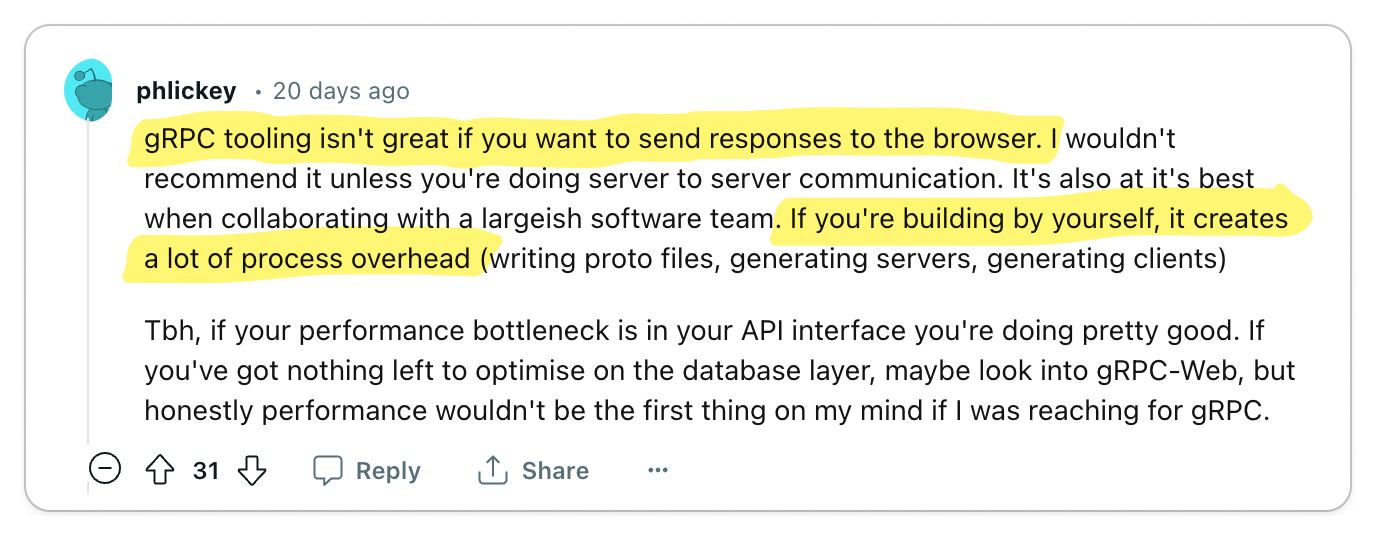
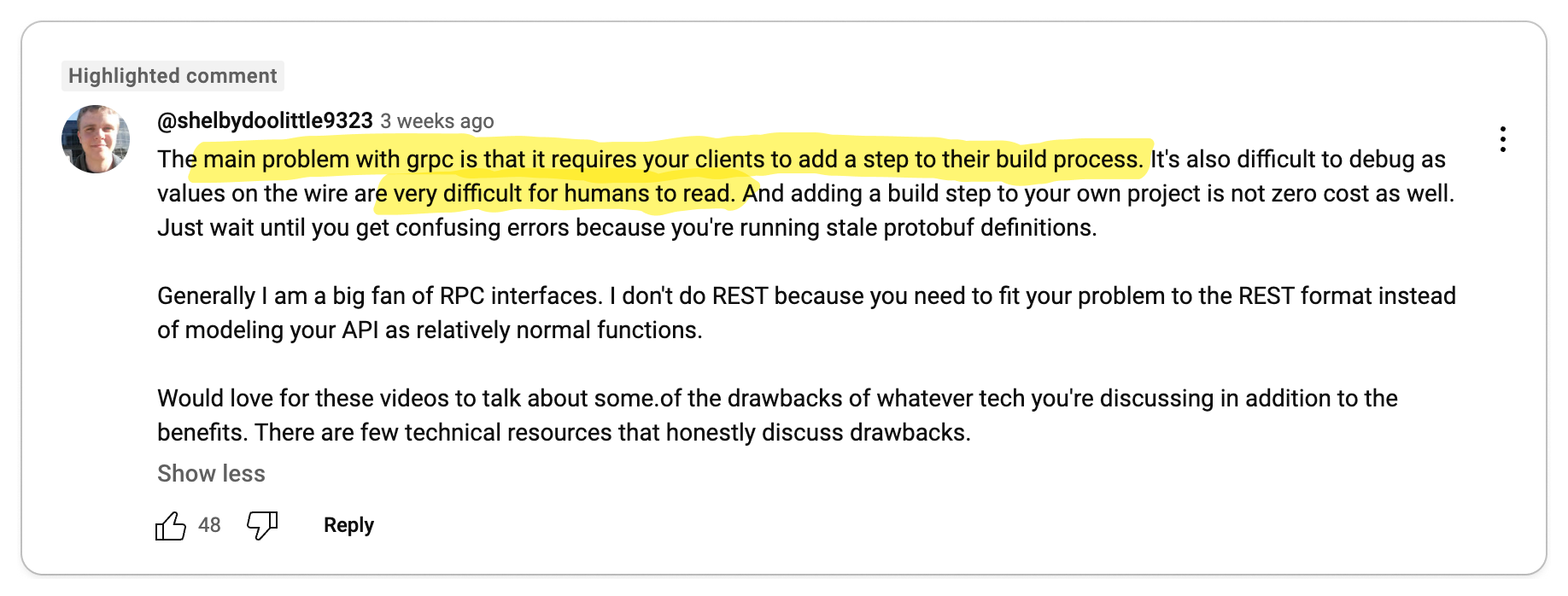
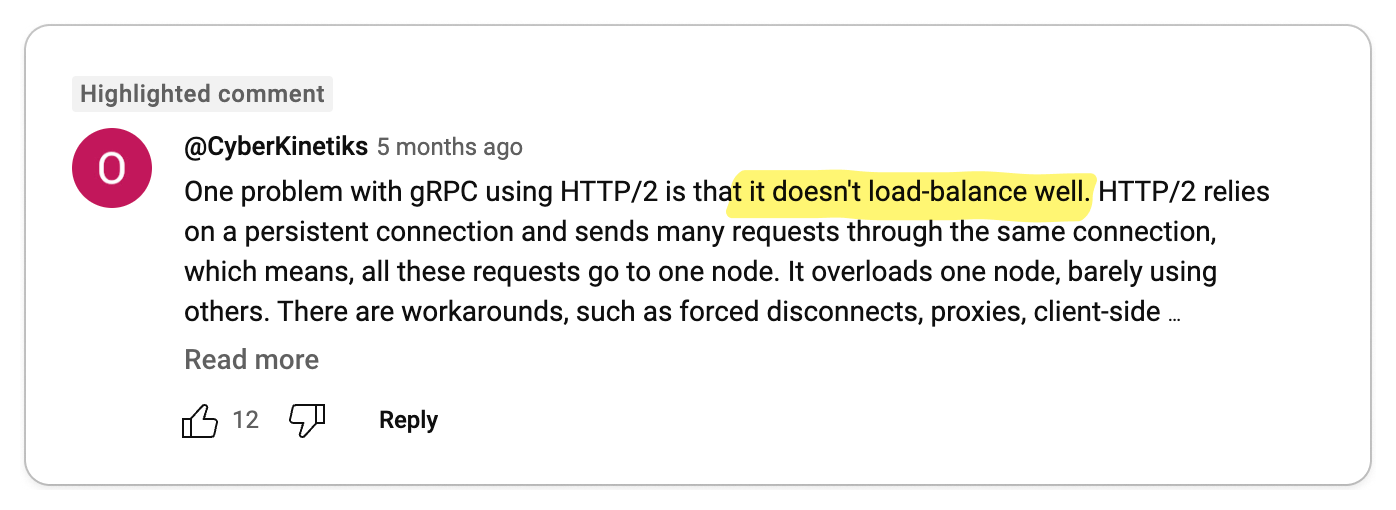
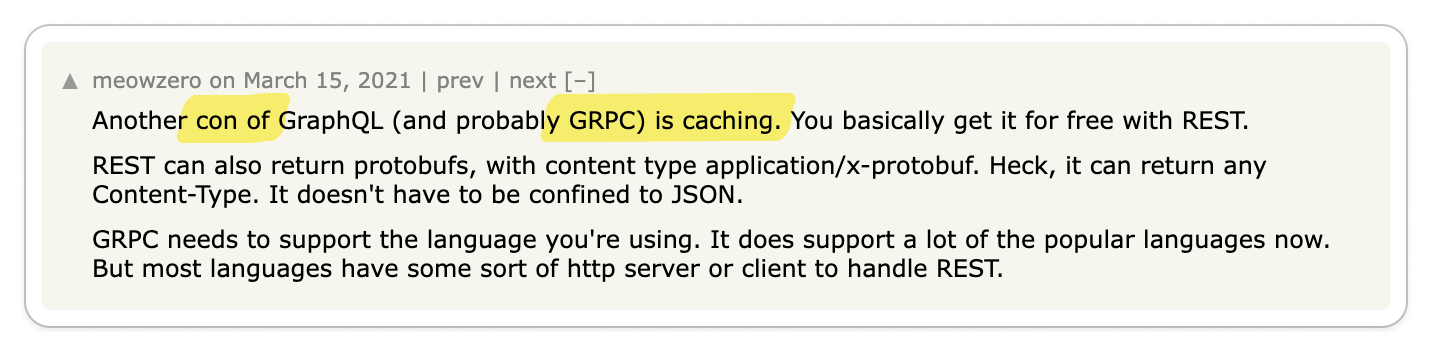
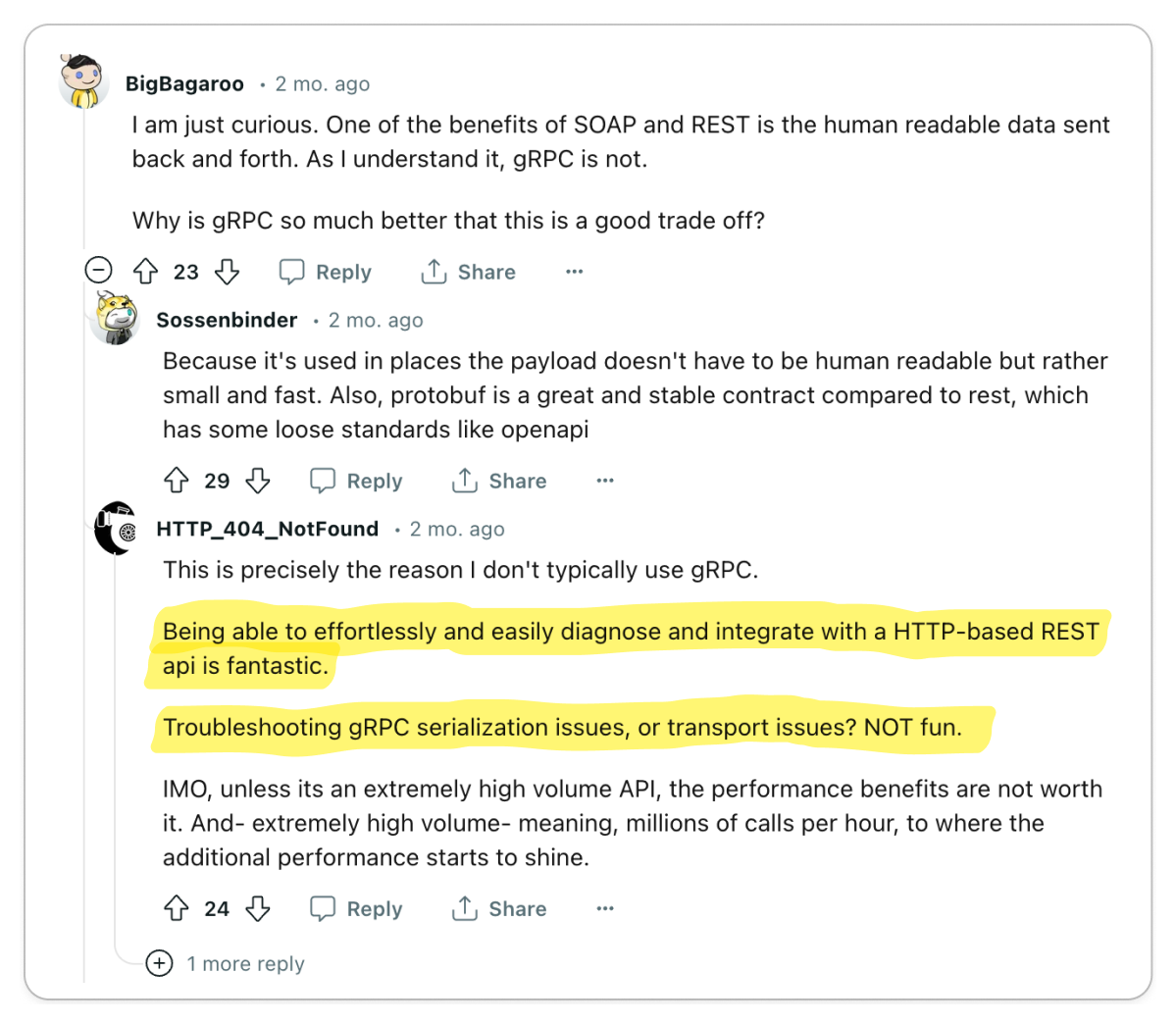
👎 gRPC complicates important things
Important functionalities like load balancing, caching, debugging, authentication and browser support are complicated by gRPC.




Key Takeaway 🔑
On the surface, gRPC appears to be a great solution for building high-quality APIs. But as with any technology, the problems start to show when you begin to use it. In particular, by adding an RPC layer, you have effectively introduced a dependency in a core part of your system. So when it comes to certain functionalities that an API is expected to provide, you are at the mercy of gRPC.
Soon, you'll start to find yourself asking questions like:
- How do I load balance gRPC services?
- How do I cache gRPC services?
- How do I debug gRPC services?
- How do I authenticate gRPC services?
- How do I support gRPC in the browser?
The list goes on. Shortly after, you'll be wondering: "Why didn't I just build a REST API?"
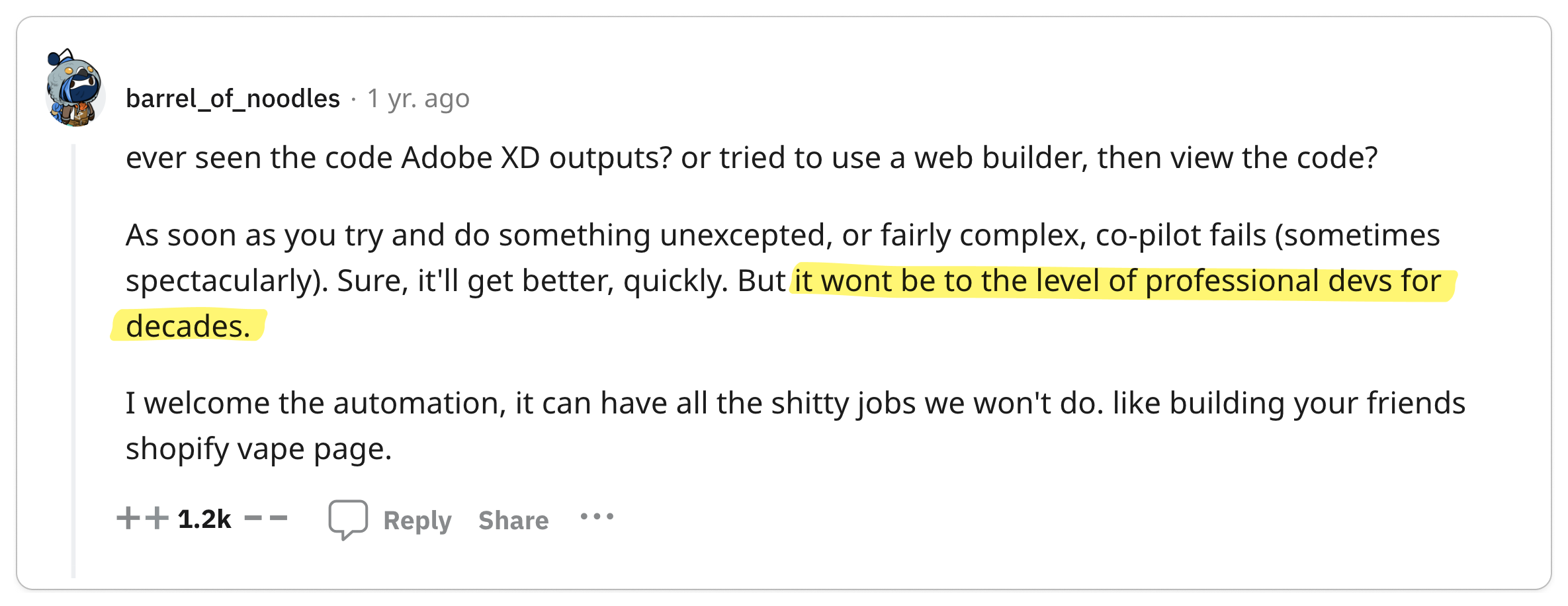
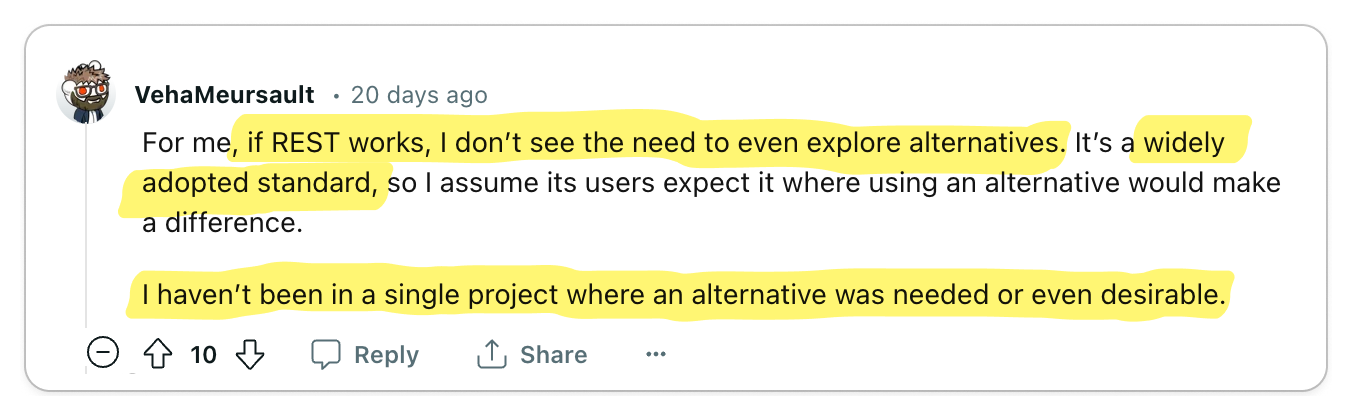
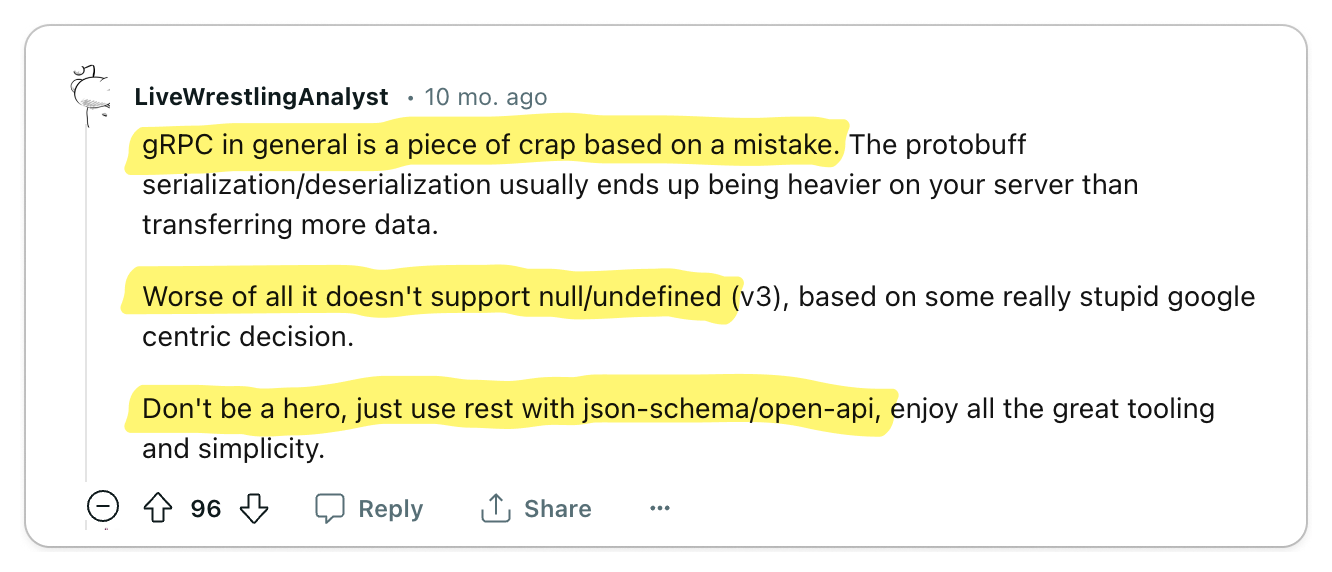
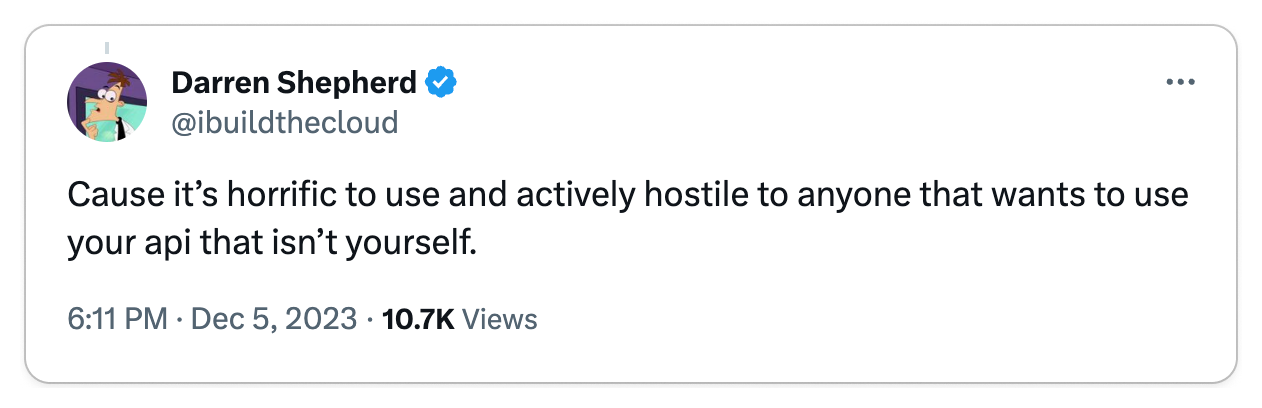
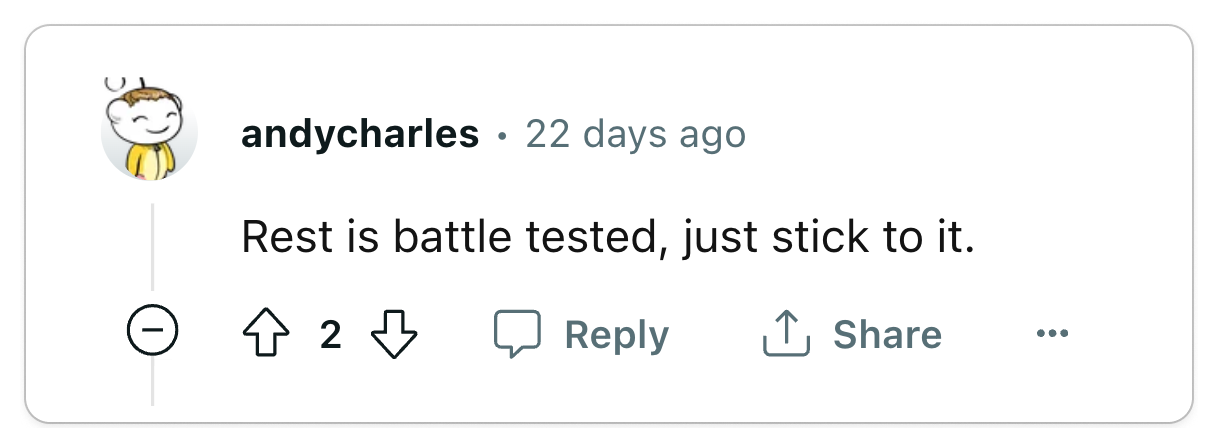
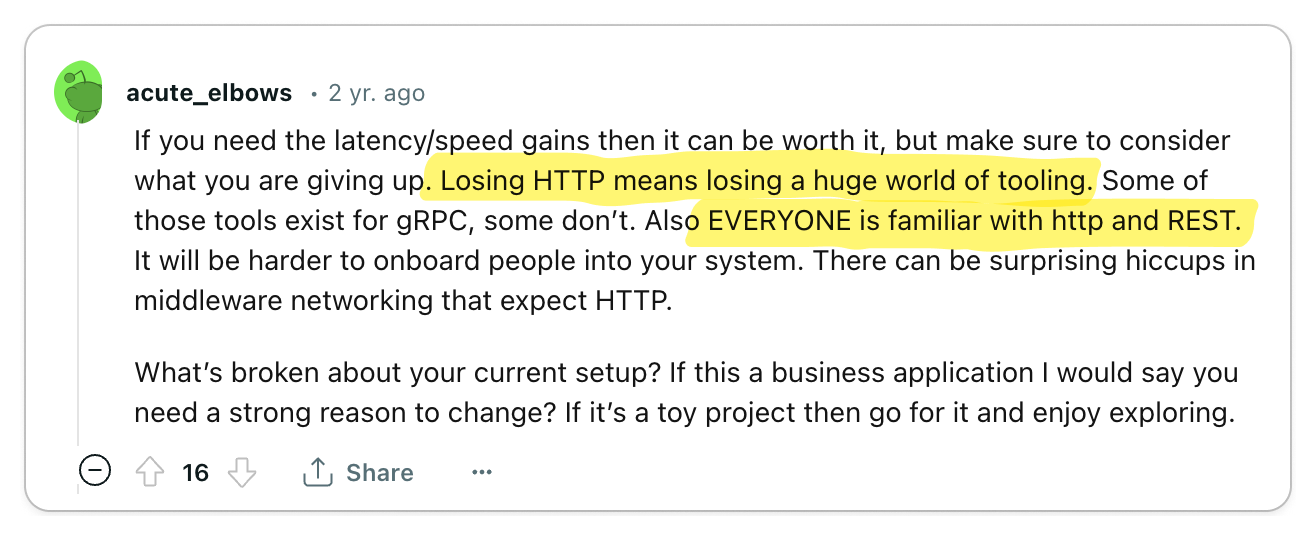
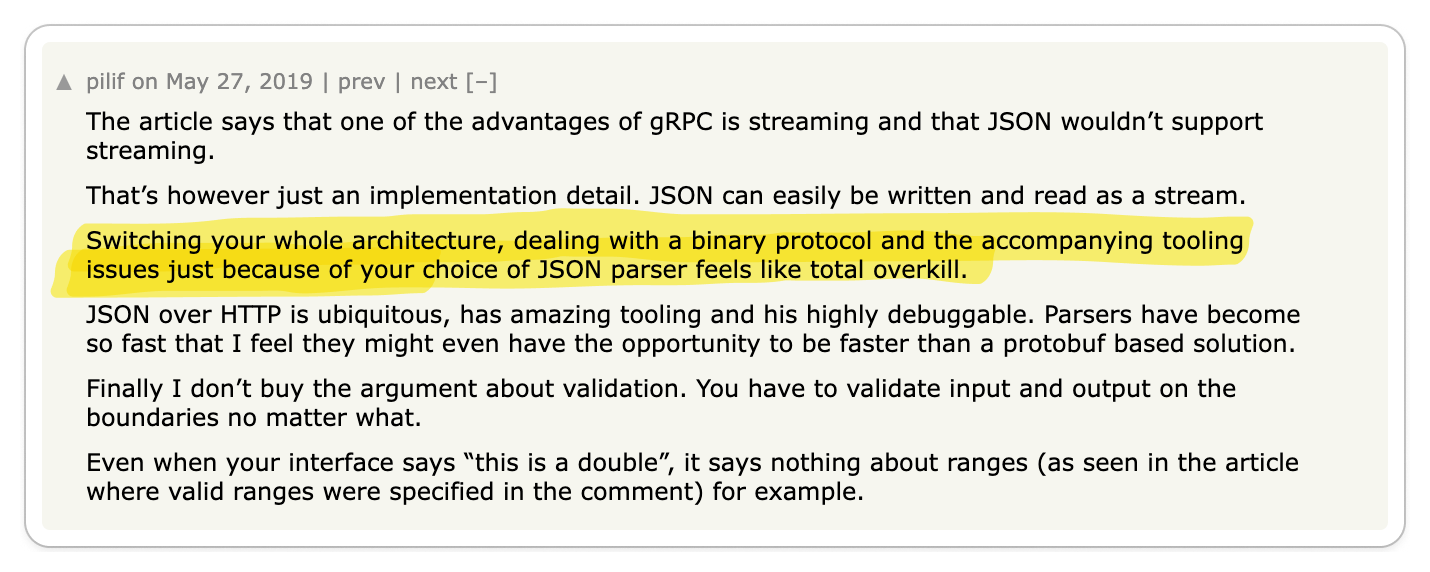
👎 REST is standard, use it
The world is built on standards and REST is no exception.

Key Takeaway 🔑
Don't be a hero, use REST.
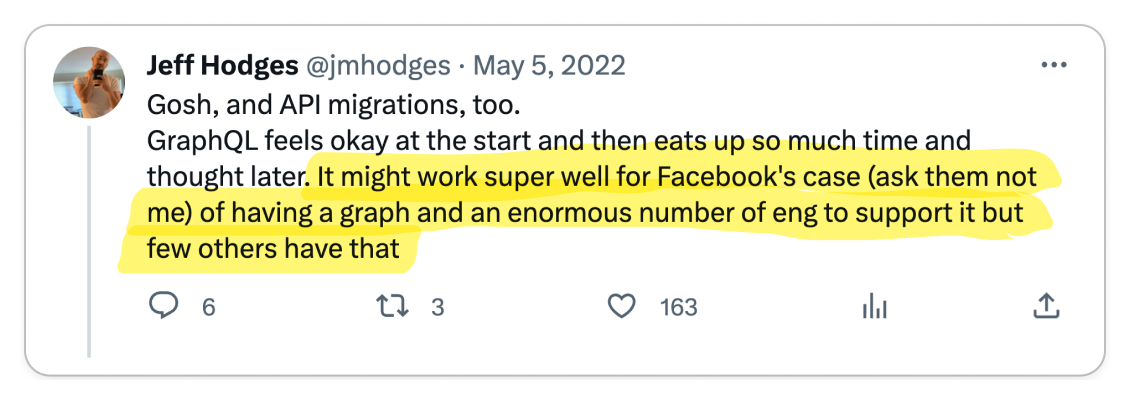
Recall that gRPC was born out of Google's need to build a high-performance service-to-service communication protocol. So practically speaking, if you are not Google, you probably don't need gRPC. Engineers often overengineer complexity into their systems and gRPC seems like a shiny new toy that engineers want to play with. But as with any new technology, you need to consider the long-term maintenance costs.
You don't want to be the one responsible for introducing new technology into your organization which becomes a burden to maintain. REST is battle-tested, so by using REST, you get all of the benefits of a standard such as tooling and infrastructure without the burden of maintaining it. Most engineers are also familiar with REST, so it's easy to onboard new developers to your team.
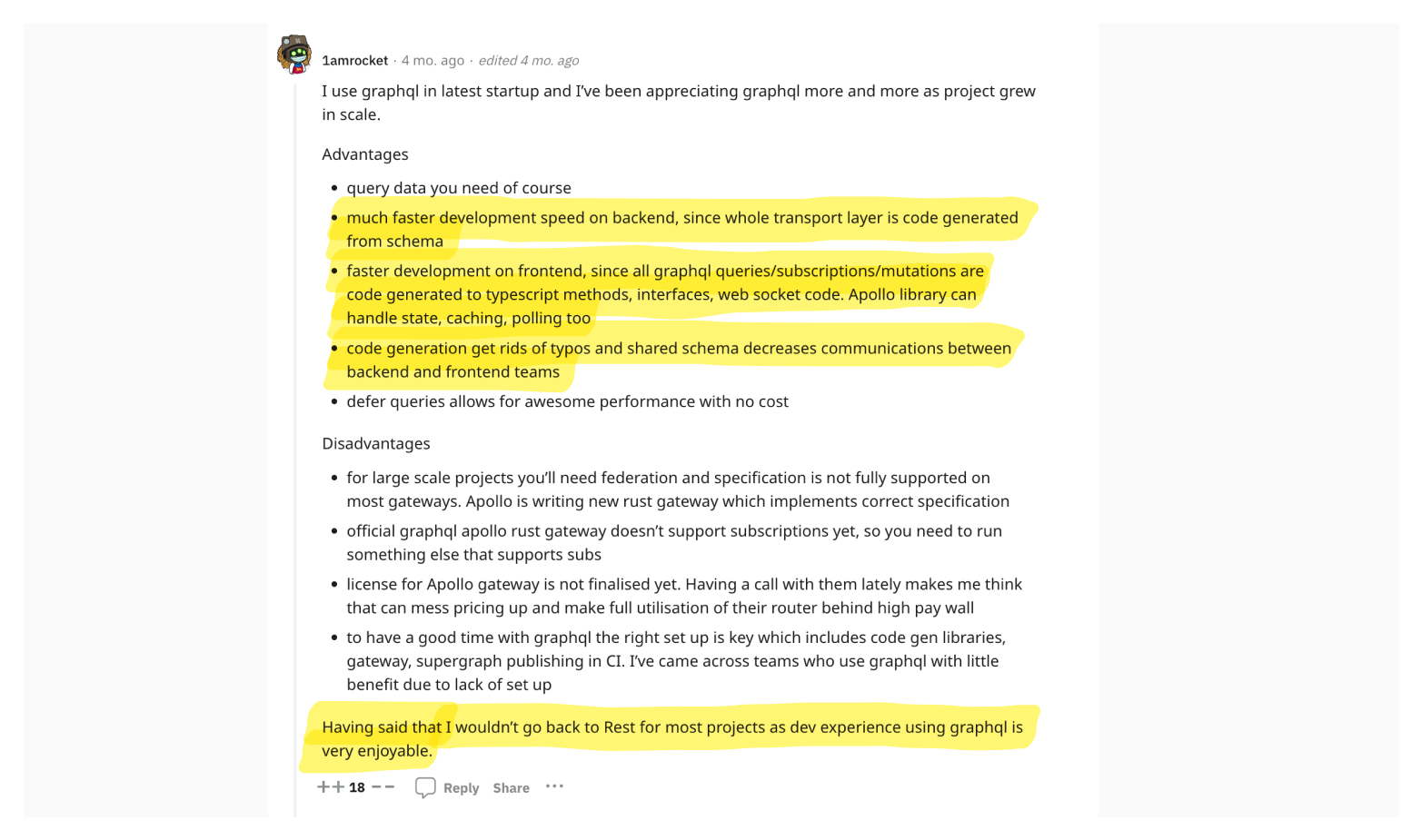
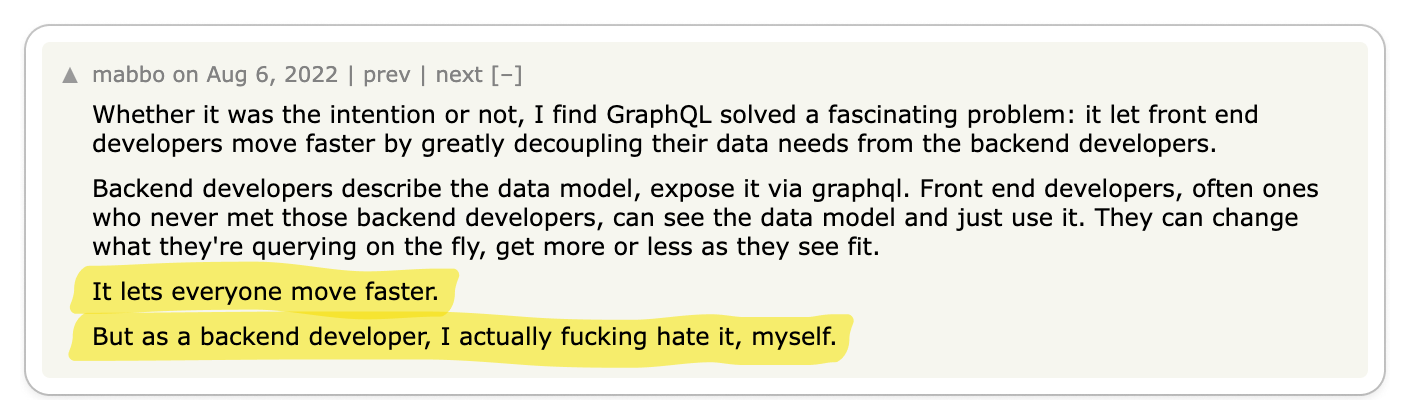
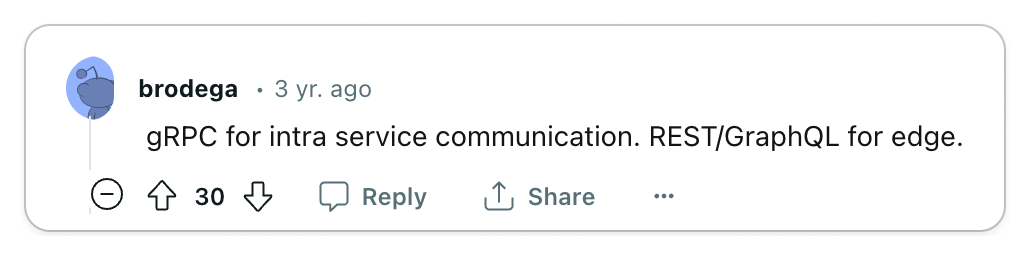
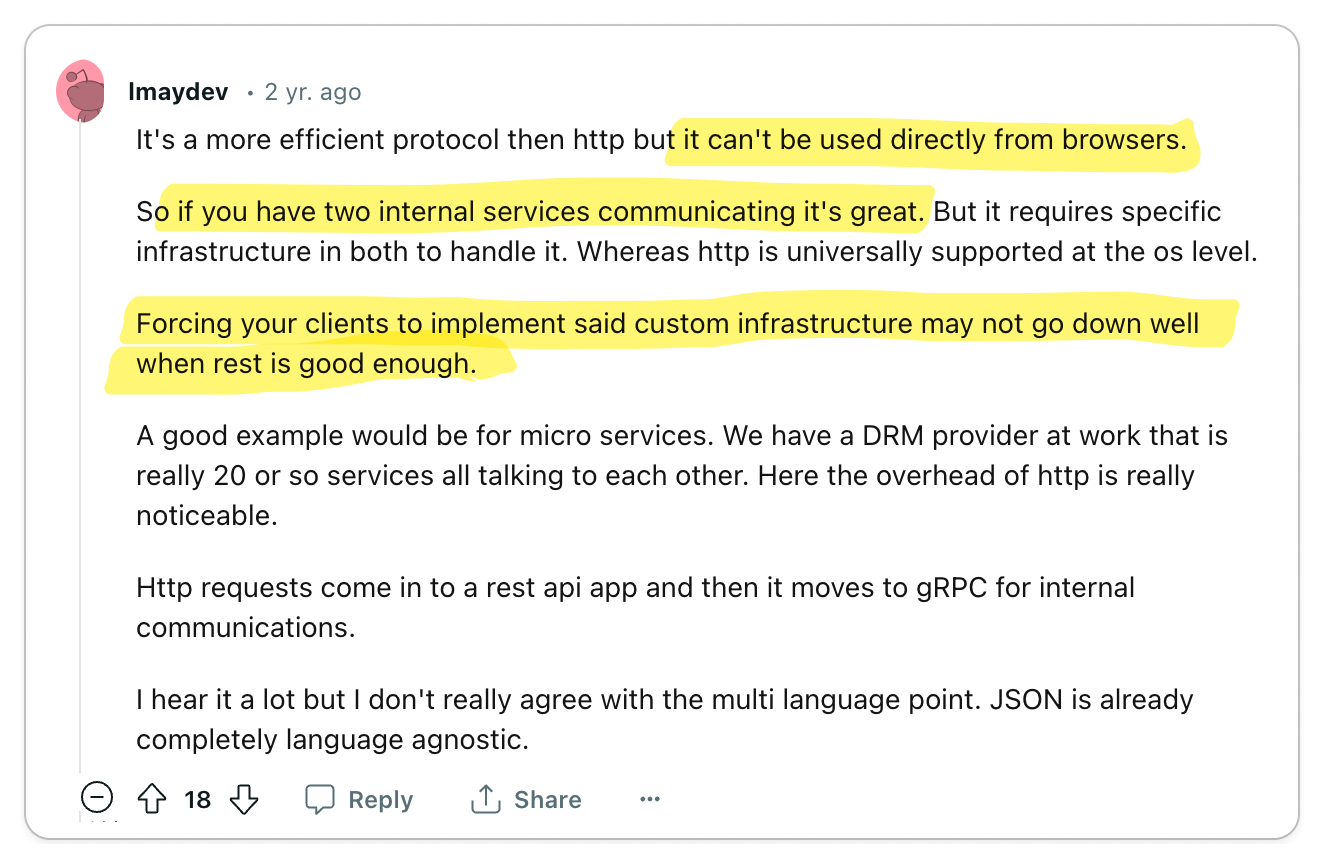
🧐 Use gRPC for internal services, REST for external services
gRPC significantly enhances the developer experience and performance for internal services. Nonetheless, it may not be the ideal choice for external services.

Key Takeaway 🔑
gRPC truly excels in internal service-to-service communication, offering developers remarkable tools for code generation and efficient data exchange. Disregarding the tangible benefits to developer experience that gRPC provides can be shortsighted, especially since many organizations could greatly benefit from its adoption.
However, it's important to note that browser support wasn't a primary focus in gRPC's design. This oversight necessitates an additional component, grpc-web, for browser accessibility. Furthermore, external services often have specific needs like caching and load balancing, which are not directly catered to by gRPC. Adopting gRPC for external services might require bespoke solutions to support these features.
Recognizing that not every technology fits all scenarios is crucial. Using gRPC for external services can be akin to trying to fit a square peg into a round hole, highlighting the importance of choosing the right tool for the right job.
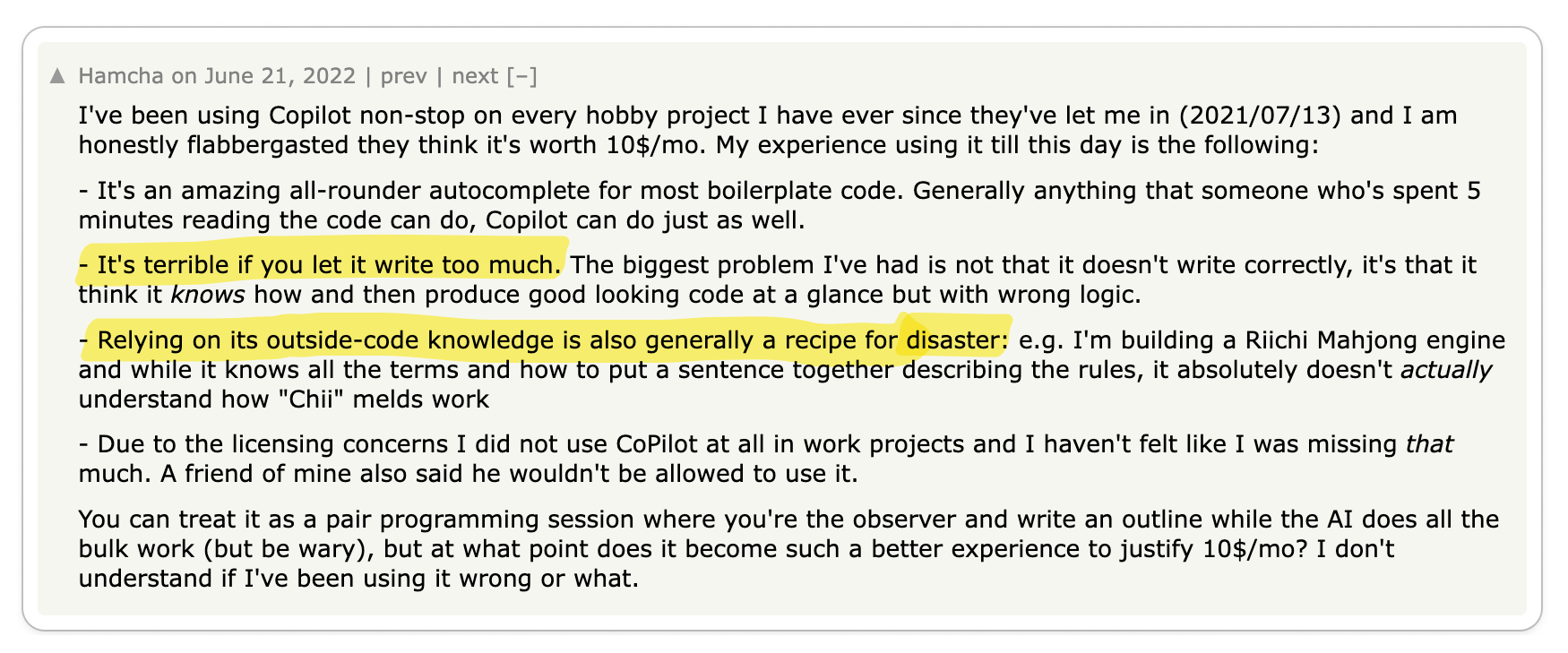
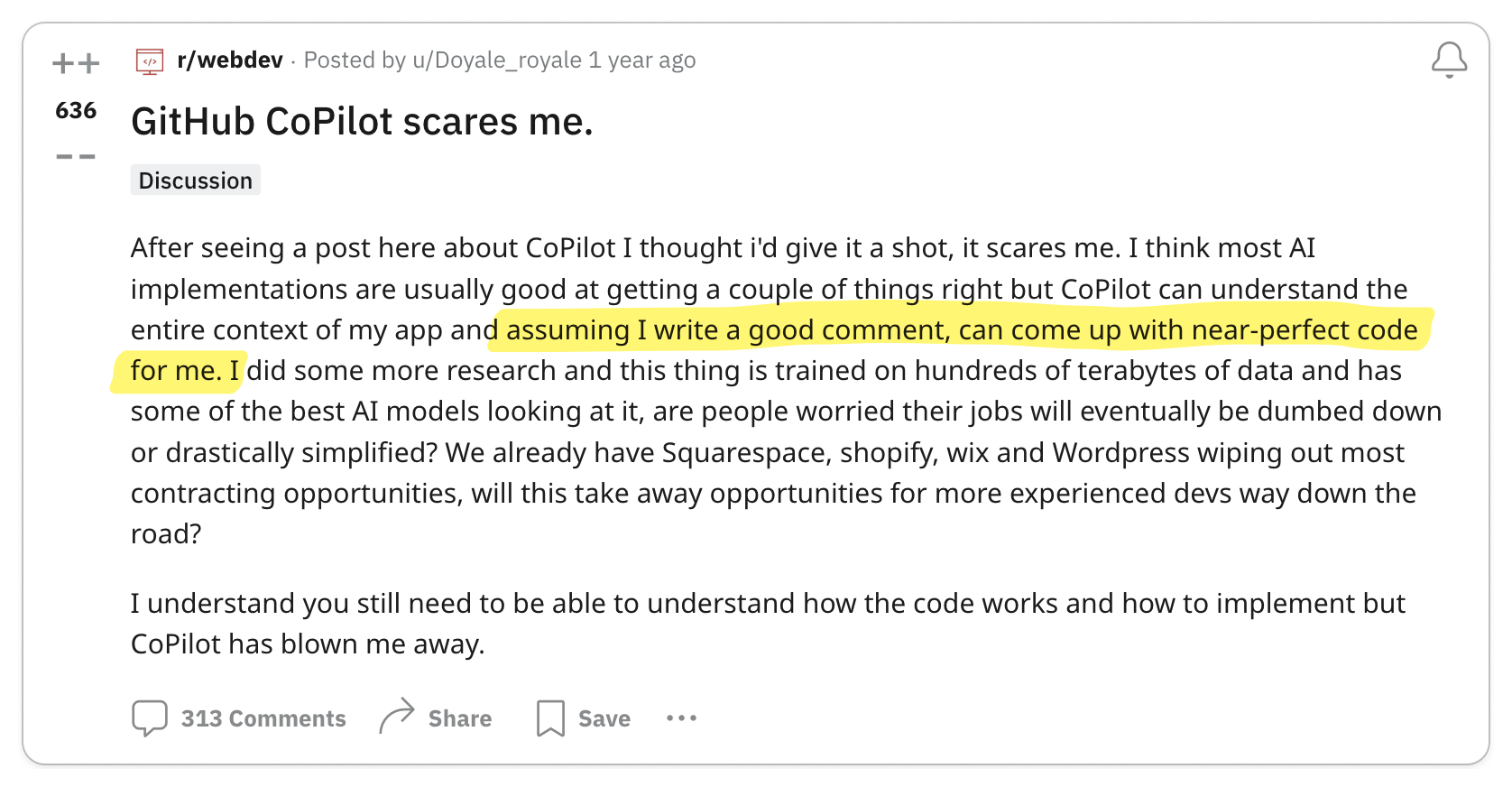
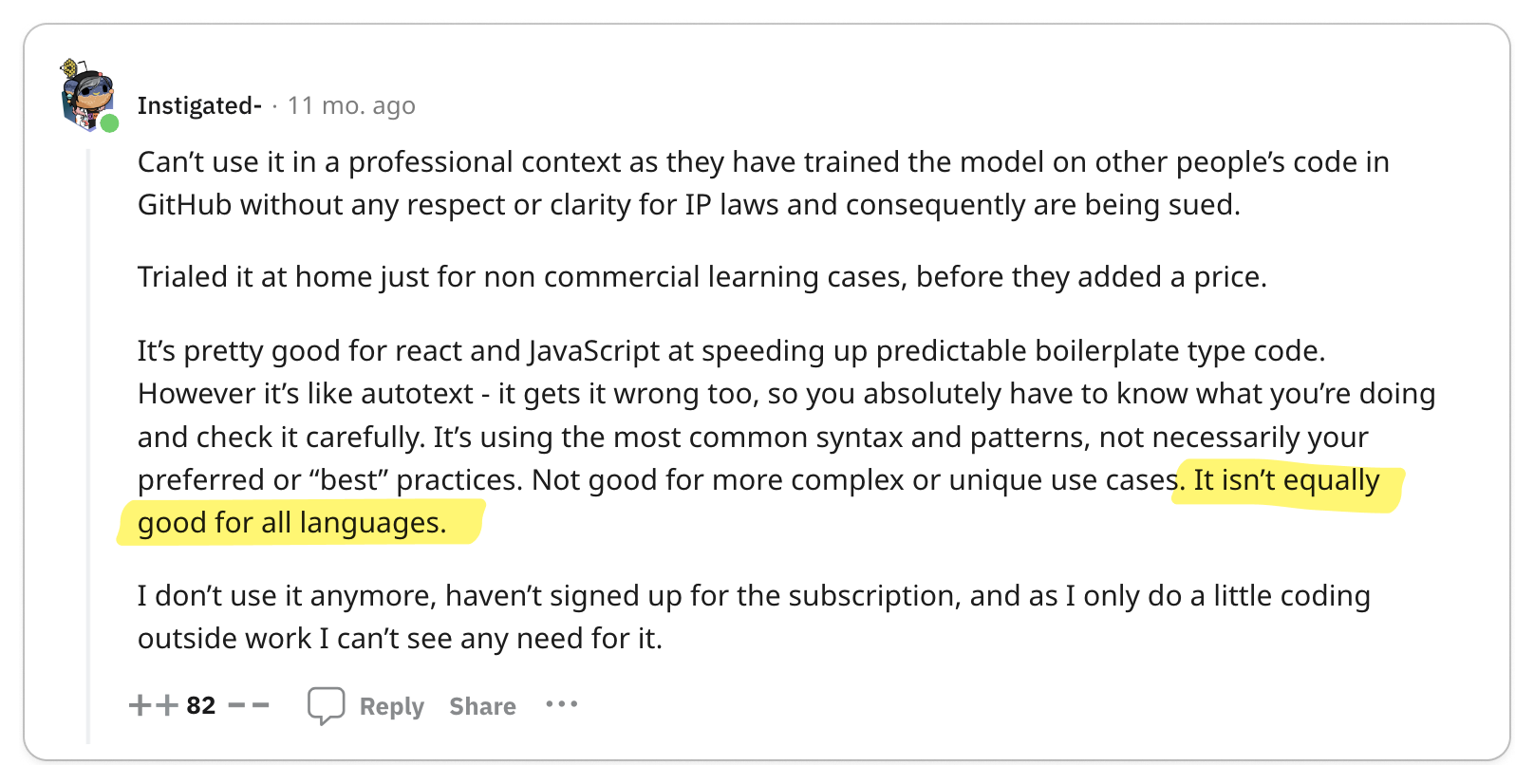
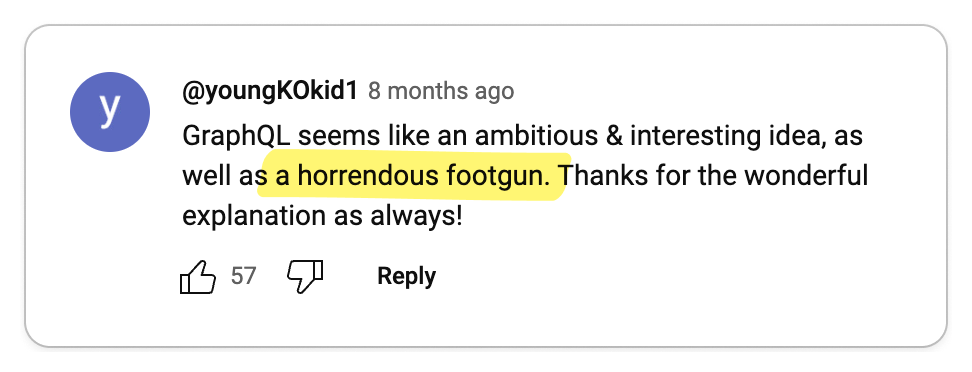
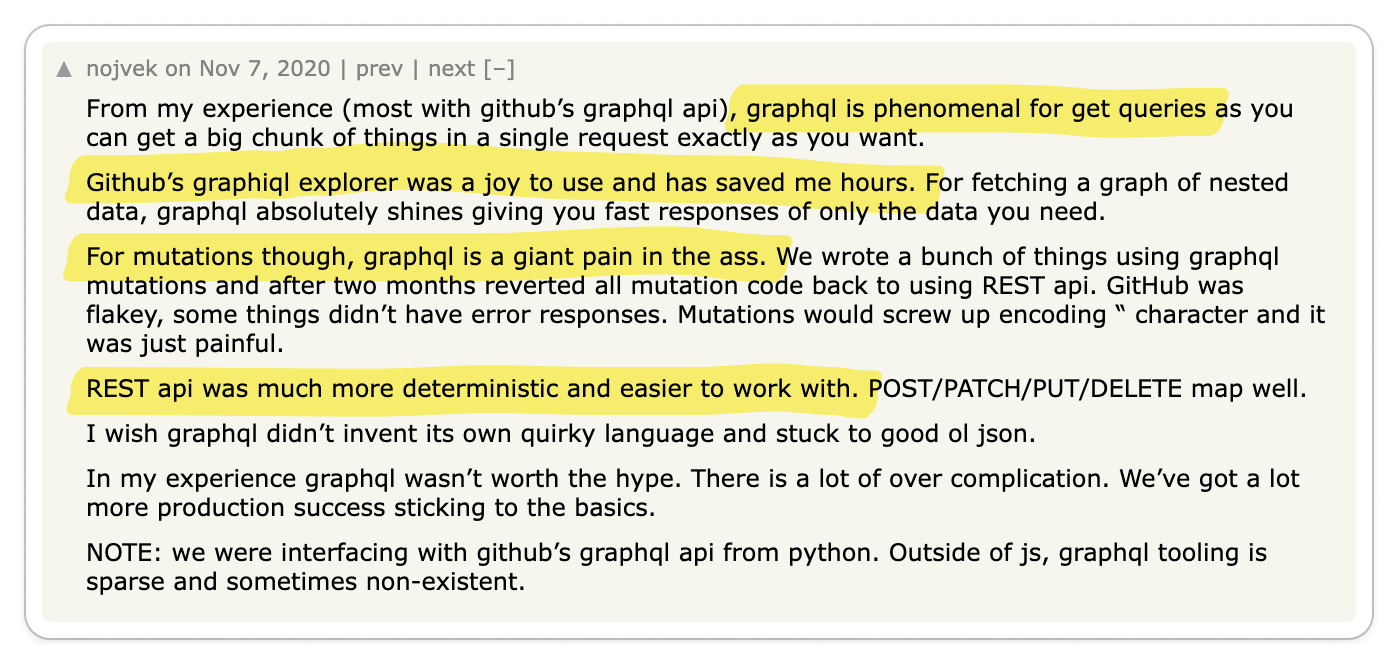
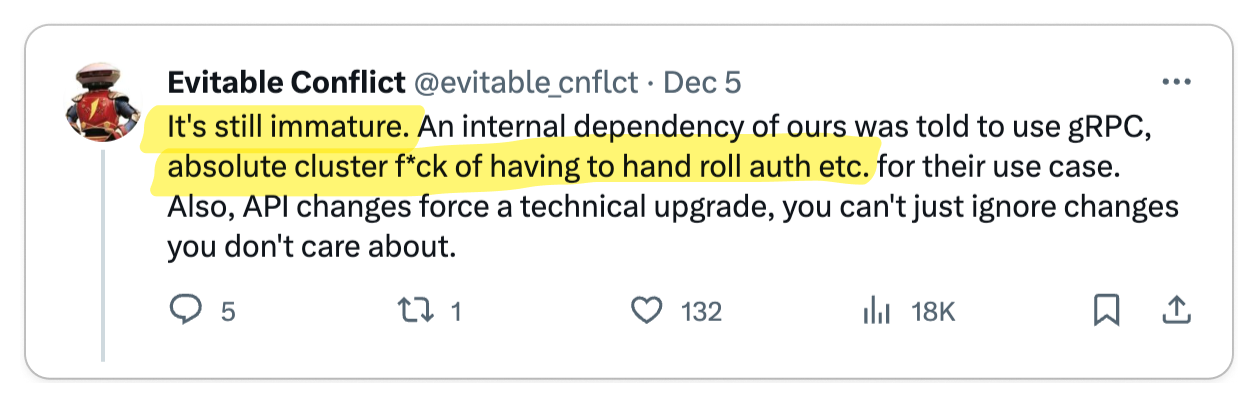
🧐 gRPC is immature
gRPC was only open sourced in 2015 when Google decided to standardize its internal RPC protocol so there is still a lot of open source tooling that needs to be built.


Key Takeaway 🔑
REST APIs are supported by a rich variety of tools, from cURL to Postman,
known for their maturity and thorough documentation. In contrast, gRPC is
comparatively younger. Although it has some tools available, they aren't as
developed or as well-documented as those for REST.
However, the gRPC ecosystem is witnessing rapid advancements with its increasing popularity. The development of open-source tools such as grpcurl and grpcui is a testament to this growth. Additionally, companies like Buf are actively contributing to this evolution by creating advanced tools that enhance the gRPC developer experience.
Conclusion
gRPC undeniably stands as a polarizing technology. It excels in enhancing developer experience and performance for internal service-to-service communications, yet some developers remain unconvinced of its advantages over REST.
In our case, we employ REST for our external API and a combination of REST/GraphQL for internal services. Currently, we see no pressing need to integrate gRPC into our workflow. However, the fervent support it garners from certain segments of the developer community is quite fascinating. It will be interesting to observe the evolution and expansion of the gRPC ecosystem in the coming years.