The default interface is shifting from humans to agents
I've been noticing a change in my own behavior lately. When I need to update a config file, run a simple command, or make a small code change, I reach for an agent instead of doing it myself. Not because I can't do it — but because it's faster and I'd rather not context-switch into the mechanical details.
This isn't laziness. It's a signal.
If even trivial tasks are better delegated to an agent, then the way we interact with every piece of software — databases, applications, codebases, infrastructure — is about to fundamentally change.
Databases: You open a GUI, write a query, click run, scan the results.
Applications: You navigate menus, fill out forms, click buttons.
Codebases: You open an editor, find the file, make the change, save.
Infrastructure: You open a console, click through dashboards, toggle settings.
Every one of these interactions assumes a human is the one doing the work. The entire surface area of modern software — every dropdown, every sidebar, every modal — exists to help a human understand and manipulate state.
But agents don't need any of that. They need APIs. They need structured, programmatic access to read state and take actions. The chrome that helps humans navigate is wasted on them.
This is the bet: the primary consumer of software interfaces is going to shift from humans to agents. And when that happens, the investment priority flips.
Old world: Build a great UI. Add an API later, maybe, if developers ask for it.
New world: Build a great API. The UI is one of many possible clients — and increasingly not the most important one.
The Model Context Protocol (MCP) is an early example of this shift. Instead of building bespoke integrations, you expose your application's capabilities as structured tools that any agent can discover and use. It's the equivalent of going from "here's a form you can fill out" to "here's a function you can call."
This changes what it means to build software:
Databases expose query and mutation endpoints that agents call directly, no SQL GUI needed.
Applications become collections of API actions that agents orchestrate on your behalf.
Codebases are navigated and modified by agents that understand the structure and can make targeted changes.
Infrastructure is managed through programmatic interfaces where agents handle the routine operational work.
The counterargument is: "Why use an agent for something that takes 10 seconds to do yourself?"
Because the real cost isn't the 10 seconds of execution. It's the context switch. It's remembering the exact flag, the exact file path, the exact syntax. It's opening the right tool, navigating to the right place, doing the thing, and then switching back to what you were actually thinking about.
An agent absorbs all of that friction. You state your intent in natural language, and the mechanical translation happens without you leaving your current train of thought. The gap between "I want this to happen" and "this happened" collapses.
And once that gap collapses for trivial tasks, it collapses for everything.
If you're building software today, the implication is clear: your API is your product. Your MCP server is your product. The programmatic surface area of your application is what agents will interact with, and agents are going to be the dominant consumers.
This doesn't mean UIs disappear. Humans still need to review, approve, and understand what's happening. But the UI shifts from being the primary interaction layer to being an oversight layer — a place where you observe and direct, not where you do the mechanical work.
The software that wins in this world is the software that's easiest for agents to use. That means clean APIs, well-documented capabilities, structured inputs and outputs, and tools that compose well.
We're moving from a world where software is designed for human hands to a world where software is designed for agent calls. Every database, every application, every codebase — the interface to all of it is going to be an agent.
From fixed-shape compute to variable-shape, memory-coupled inference
For years, production ML looked like images or fixed-duration signals—tight, predictable tensors. You sized for FLOPs, picked a batch size, and rode the throughput curve.
LLMs changed the physics: inputs and outputs vary; attention cost grows with sequence length; decoding accumulates a KV cache that ties compute to memory capacity and bandwidth. Prefill and decode are different workloads. Add MoE routing and quantization, and the hot path keeps moving.
Old world:
Fixed shapes, stable FLOPs, single dominant bottleneck (compute)
Quantization: 2/3/4/8-bit trade speed, quality, and kernel availability
Many first-order variables: length distributions, concurrency, cache hit rate, expert sparsity, scheduler policy
The knobs move with the workload, not just the hardware. Kernel block sizes, KV cache configs, sequence/tensor parallelism, and schedulers (batching windows, priority, admission control) must adapt to what’s actually arriving.
Optimization is also use-case dependent: interactive chatbots target low
TTFT/p50; large async/batch jobs target max throughput and cost efficiency. That
means different batching windows, prioritization of prefill vs. decode, and
distinct quantization/parallelism choices per tier.
What to do:
Instrument length and cache-hit distributions; set SLOs by percentiles
Separate or phase-aware schedule prefill vs. decode
Use KV caches with explicit memory budgets and eviction policies
Dynamic batching with latency guardrails and backpressure/admission control
Route MoE and multi-model traffic by tier; co-locate hot experts; manage cold starts
Choose quantization per tier; align with available kernels and target SLOs
Re-tune continuously; treat inference as a control system, not a fixed config
Bottom line: LLM inference breaks simple queueing. Optimal performance is workload-dependent and multi-dimensional—compute, memory, state, routing, and bits. Measure, adapt, and schedule accordingly.
The shift: from unit tests to benchmarks in the LLM era
Traditional testing assumed deterministic, fast code. You could run thousands of unit tests in seconds because each test took microseconds-milliseconds and had a single correct answer.
Old world:
10,000 unit tests x 1 ms ≈ 10 seconds → easy to run on every commit.
End-to-end tests were slower and run infrequently.
LLM-powered apps flip this: calls are slow (network + model), stochastic, and paid. They're also your core business logic.
New world:
1,000 LLM tests x 5-10 s ≈ 1.5-3 hours per run.
10,000 tests ≈ 14-28 hours, plus real API cost.
Running that on every change is impossible.
The strategy shifts from exhaustive unit tests to benchmarks:
Curate fixed eval sets, score with clear metrics, track a baseline.
Run tiny “smoke” evals (5-20 cases) on every change.
Run full benchmarks nightly/weekly; gate major releases on deltas.
Monitor in production and refresh the benchmark set regularly.
Bottom line: Deterministic unit tests don't scale to LLMs. Benchmarks and periodic, statistical evaluation are the new way to ensure quality without freezing velocity.
Note: Continuously improving from production data—instrumentation, human/auto grading, error triage, and iterative prompt/model updates—is its own discipline: the evals flywheel. That's food for a separate discussion.
Lately i've been seeing all this craze about MCP. And the other day, my
colleague was also wondering what exactly MCP does and why it has been trending
recently. Since the current tool calling paradigm does not really seem to be
broken at the surface. But after reading a bit more about it, I have a simple
example that shows why MCP is a good idea.
Lets take a simple example of how you would have connected LLMs to external
tools before MCP.
main.py
from openai import OpenAI client = OpenAI() defget_capital(country:str)->str: # This is a mock function that returns the capital of a country return"Washington, D.C." response = client.chat.completions.create( model="gpt-4o", messages=[ {"role":"system","content":"You are a helpful assistant."}, {"role":"user","content":"What is the capital of the moon?"}, ], tools=[ { "type":"function", "function":{"name":"get_capital","description":"Get the capital of a country","parameters":{"type":"string","name":"country"}}, } ], ) tool_calls = response.choices[0].message.tool_calls for tool_call in tool_calls: if tool_call.function.name =="get_capital": country = tool_call.function.arguments["country"] capital = get_capital(country) print(f"The capital of {country} is {capital}")
This is a very simple example, and you can see that the tool calling paradigm
does not standout as broken. You can accomplish what you need to do with the
current paradigm.
But now, lets say that you want to add another tool that can do a web search.
main.py
defweb_search(query:str)->str: # This is a mock function that returns the first result of a web search return"https://www.google.com" ... response = client.chat.completions.create( model="gpt-4o", messages=[ {"role":"system","content":"You are a helpful assistant."}, {"role":"user","content":"What is the capital of the moon?"}, ], tools=[ { "type":"function", "function":{"name":"get_capital","description":"Get the capital of a country","parameters":{"type":"string","name":"country"}}, }, { "type":"function", "function":{"name":"web_search","description":"Search the web for information","parameters":{"type":"string","name":"query"}}, } ], ) tool_calls = response.choices[0].message.tool_calls for tool_call in tool_calls: if tool_call.function.name =="get_capital": country = tool_call.function.arguments["country"] capital = get_capital(country) print(f"The capital of {country} is {capital}") if tool_call.function.name =="web_search": query = tool_call.function.arguments["query"] result = web_search(query) print(f"The first result of {query} is {result}")
The key takeaway here is that for each tool call, you need to write a new
function. While manageable for a few tools, this quickly becomes unscalable as
your toolset grows. You end up maintaining complex dispatch logic and tight
coupling between your app and tool implementations.
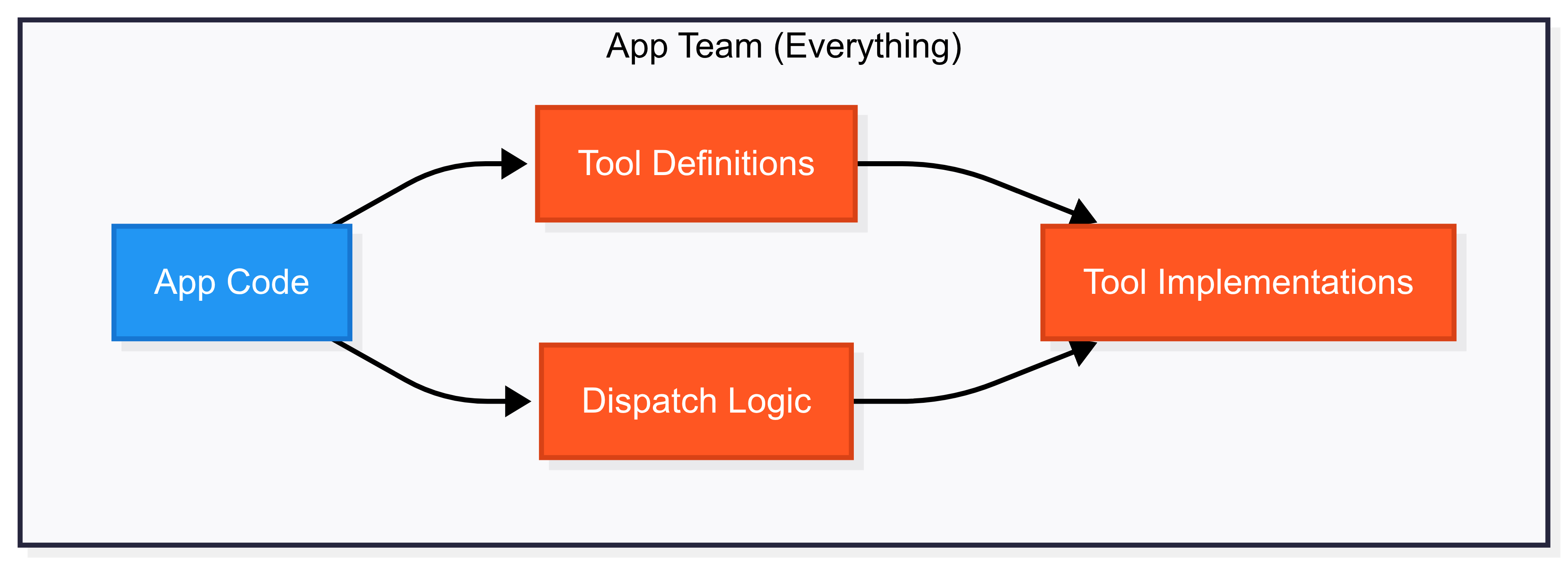
Application code handles tool calls before MCP
With MCP, you write your client code once and modularly add new tools as you
need them. This separates the responsibility for tool call implementation from
the application code. Like good software architecture, MCP enables teams to
work independently without tight coupling.
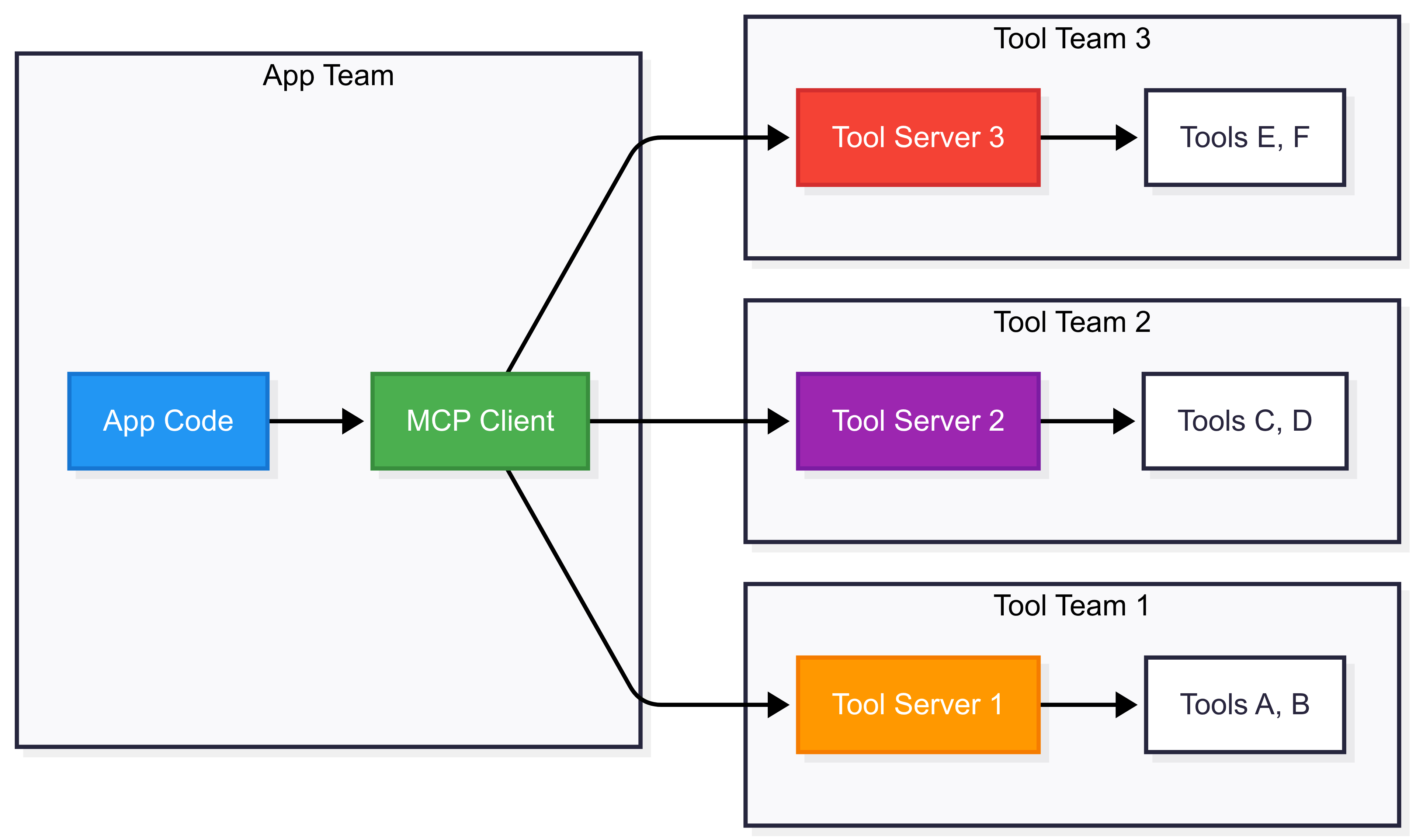
Separation of code between the app and the tool teams after MCP
asyncdefprocess_query(self, query:str)->str: """Process a query using Claude and available tools""" messages =[ { "role":"user", "content": query } ] response =await self.session.list_tools() available_tools =[{ "name": tool.name, "description": tool.description, "input_schema": tool.inputSchema }for tool in response.tools] # Initial Claude API call response = self.anthropic.messages.create( model="claude-3-5-sonnet-20241022", max_tokens=1000, messages=messages, tools=available_tools ) # Process response and handle tool calls final_text =[] assistant_message_content =[] for content in response.content: if content.type=='text': final_text.append(content.text) assistant_message_content.append(content) elif content.type=='tool_use': tool_name = content.name tool_args = content.input # Execute tool call result =await self.session.call_tool(tool_name, tool_args) final_text.append(f"[Calling tool {tool_name} with args {tool_args}]") assistant_message_content.append(content) messages.append({ "role":"assistant", "content": assistant_message_content }) messages.append({ "role":"user", "content":[ { "type":"tool_result", "tool_use_id": content.id, "content": result.content } ] }) # Get next response from Claude response = self.anthropic.messages.create( model="claude-3-5-sonnet-20241022", max_tokens=1000, messages=messages, tools=available_tools ) final_text.append(response.content[0].text) return"\n".join(final_text)
The key line of code is self.session.list_tools(), which would return a list of
tools like the web search one we added earlier.
web_search.json
{ "type": "function", "function": {"name": "web_search", "description": "Search the web for information", "parameters": {"type": "string", "name": "query"}}, }
This is what makes MCP powerful. Now, what is session and how does it
magically know about all the tools?
Well, thats where MCP comes in. Since MCP standardizes the way that tools are
discovered, you can create a single MCPClient that can be used to call any
tool.
mcp_client.py
import asyncio from typing import Optional from contextlib import AsyncExitStack from mcp import ClientSession, StdioServerParameters from mcp.client.stdio import stdio_client from anthropic import Anthropic from dotenv import load_dotenv load_dotenv()# load environment variables from .env classMCPClient: def__init__(self): # Initialize session and client objects self.session: Optional[ClientSession]=None self.exit_stack = AsyncExitStack() self.anthropic = Anthropic() asyncdefprocess_query(self, query:str): """Includes the code above from tool_call_with_mcp.py""" ... asyncdefconnect_to_server(self, server_script_path:str): """Connect to an MCP server Args: server_script_path: Path to the server script (.py or .js) """ is_python = server_script_path.endswith('.py') is_js = server_script_path.endswith('.js') ifnot(is_python or is_js): raise ValueError("Server script must be a .py or .js file") command ="python"if is_python else"node" server_params = StdioServerParameters( command=command, args=[server_script_path], env=None ) stdio_transport =await self.exit_stack.enter_async_context(stdio_client(server_params)) self.stdio, self.write = stdio_transport self.session =await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write)) await self.session.initialize() # List available tools response =await self.session.list_tools() tools = response.tools print("\nConnected to server with tools:",[tool.name for tool in tools]) asyncdefcleanup(self): """Clean up resources""" await self.exit_stack.aclose()
Notice how we have a session that was initialized with an interface to the
provided server script. You can insantiate multiple MCP clients, each with their
own unique server script, and they will all be able to call the tools provided
by the server script. In this example, we have a single MCP client, but you can
easily imagine how you would add more clients to your application by
instantiating a list of MCP clients: [MCPClient(), MCPClient(), ...].
Then, you can write an entrypoint for your application that would call the
MCPClient and pass it the path to the server script.
main.py
asyncdefmain(): iflen(sys.argv)<2: print("Usage: python client.py <path_to_server_script>") sys.exit(1) client = MCPClient() try: await client.connect_to_server(sys.argv[1]) await client.process_query("What is the capital of the moon?") finally: await client.cleanup() if __name__ =="__main__": import sys asyncio.run(main())
Notice how this can be done programatically through a CLI. This is where
application developers would allow users to programatically plugin MCP servers
to provide their application with more tools, amplifying the capabilities of the
application.
MCP is a new tool calling paradigm that allows application developers to
programatically provide LLMs with access to external tools without having to
worry about the underlying implementation details of the tool call interfaces.
MCP actually does even more than this modular tool integration to give LLMs more
context and higher tool usage accuracy, but I suspect this modular tool
integration was the core impetus for its invention.
Recently I shared my startup journey on LinkedIn. In
particular, I shared the source code for my startup after closing it down along
with the story of building and shutting down the company. Ordinarily, I got an
above-average response from my personal network since it was big career news for
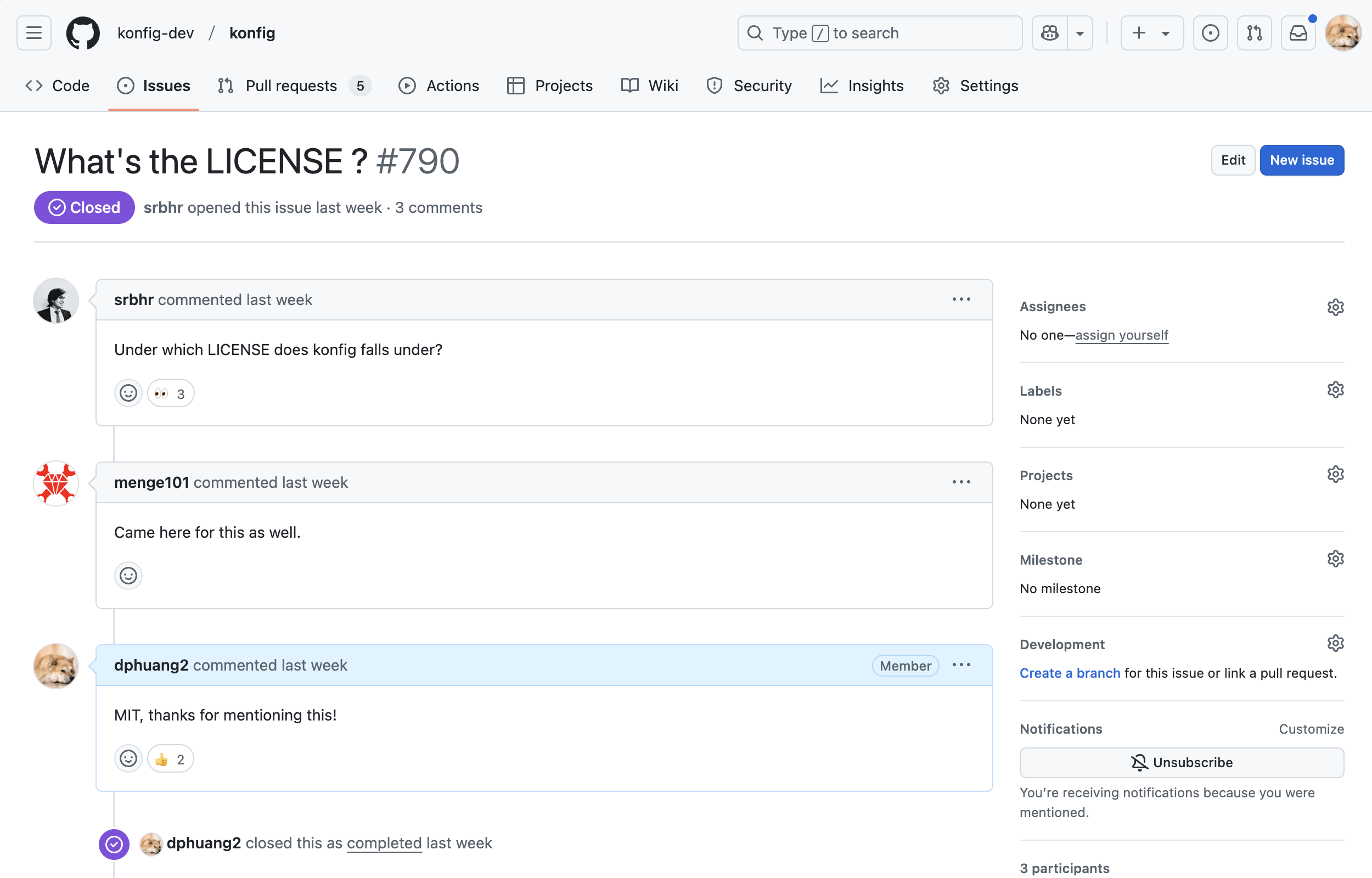
me. But as I woke up the next day, I saw a pull request on the open source repo
asking to license the code—which was weird because I didn't think anybody would
actually care about a failed startup's codebase.
Screenshot of the GitHub Issue that was created at 5AM PST while I was asleep
Similarly weird, there were ~50 stars on the repo. Curious about where this sudden
attention was coming from, I checked my website analytics and noticed a surge of
traffic from both Hacker News and Reddit. Someone had discovered my post and
shared it on both platforms where it quickly gained traction. Over the next 6
days, my story reached over 100,000 readers, I received more than 100
recruitment messages, and the GitHub repo accumulated over 1,000 stars. What
started as a simple LinkedIn post about my startup journey had organically spread
to /r/programming
and HackerNews, sparking
discussions in both communities.
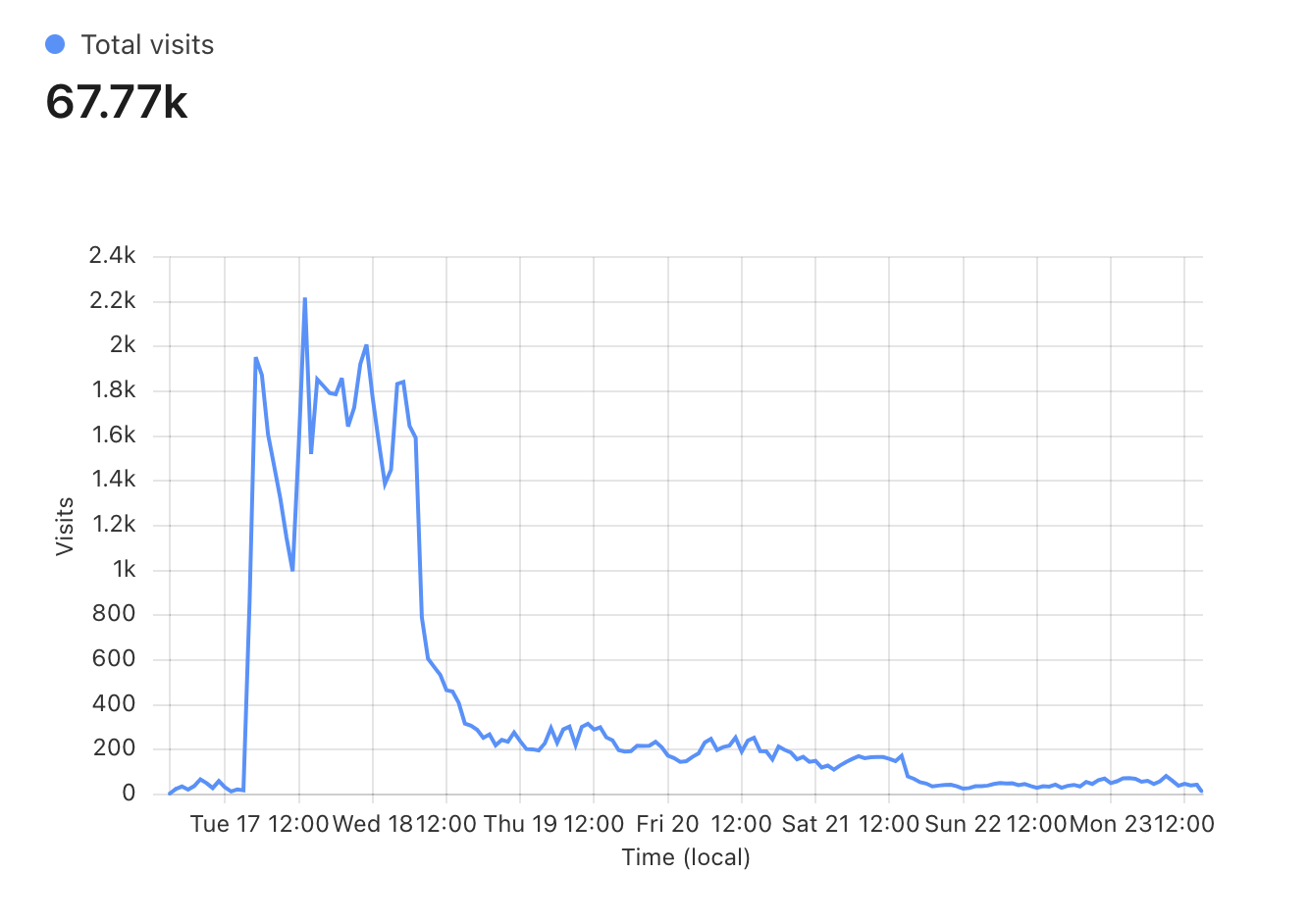
Here is a screenshot of website page views from Cloudflare.
Screenshot of web analytics from Cloudflare showing page views over the past 7 days (12-16-2024 to 12-23-2024)
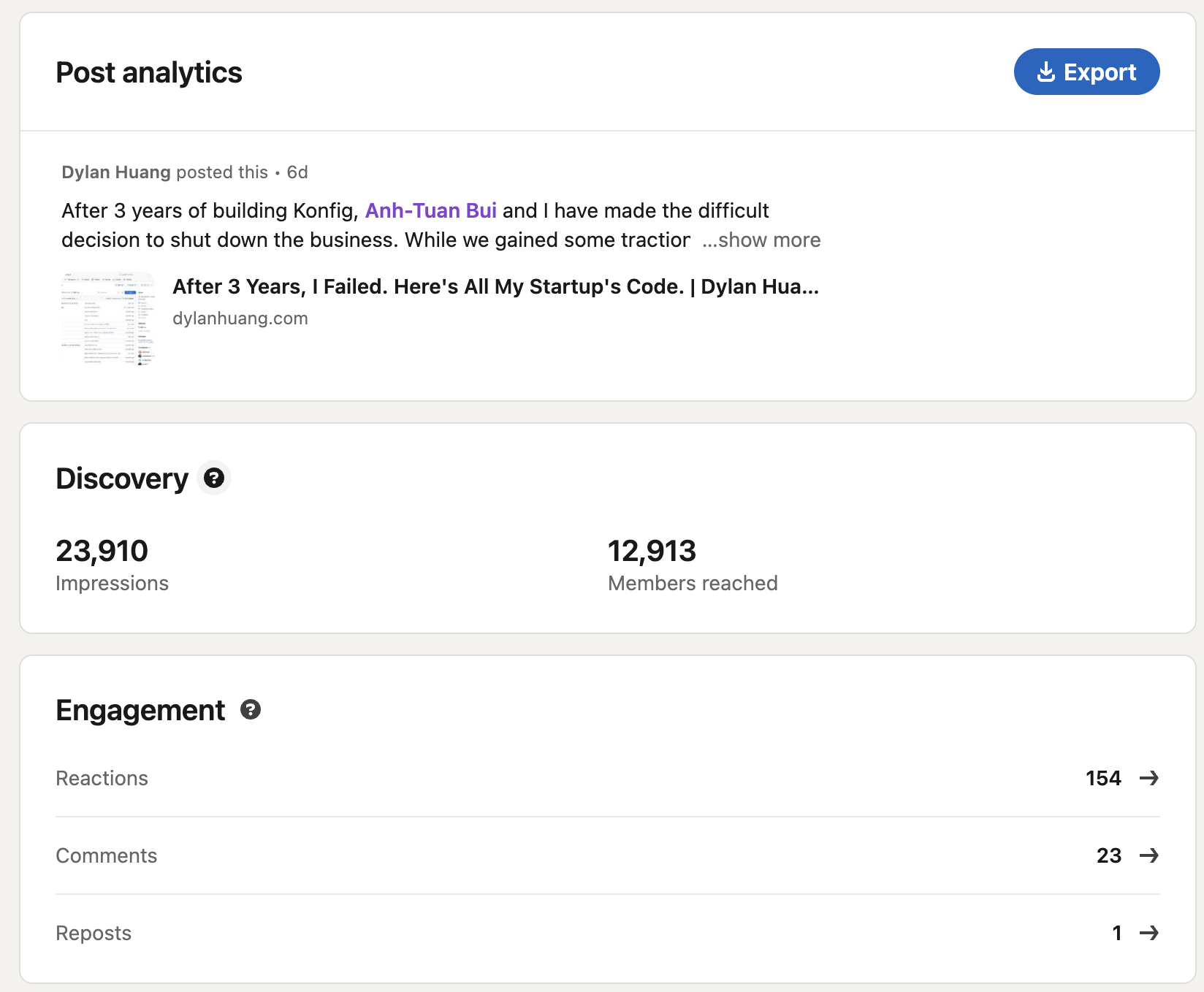
Analytics from LinkedIn:
Screenshot of Post analytics from LinkedIn taken on 12-23-2024
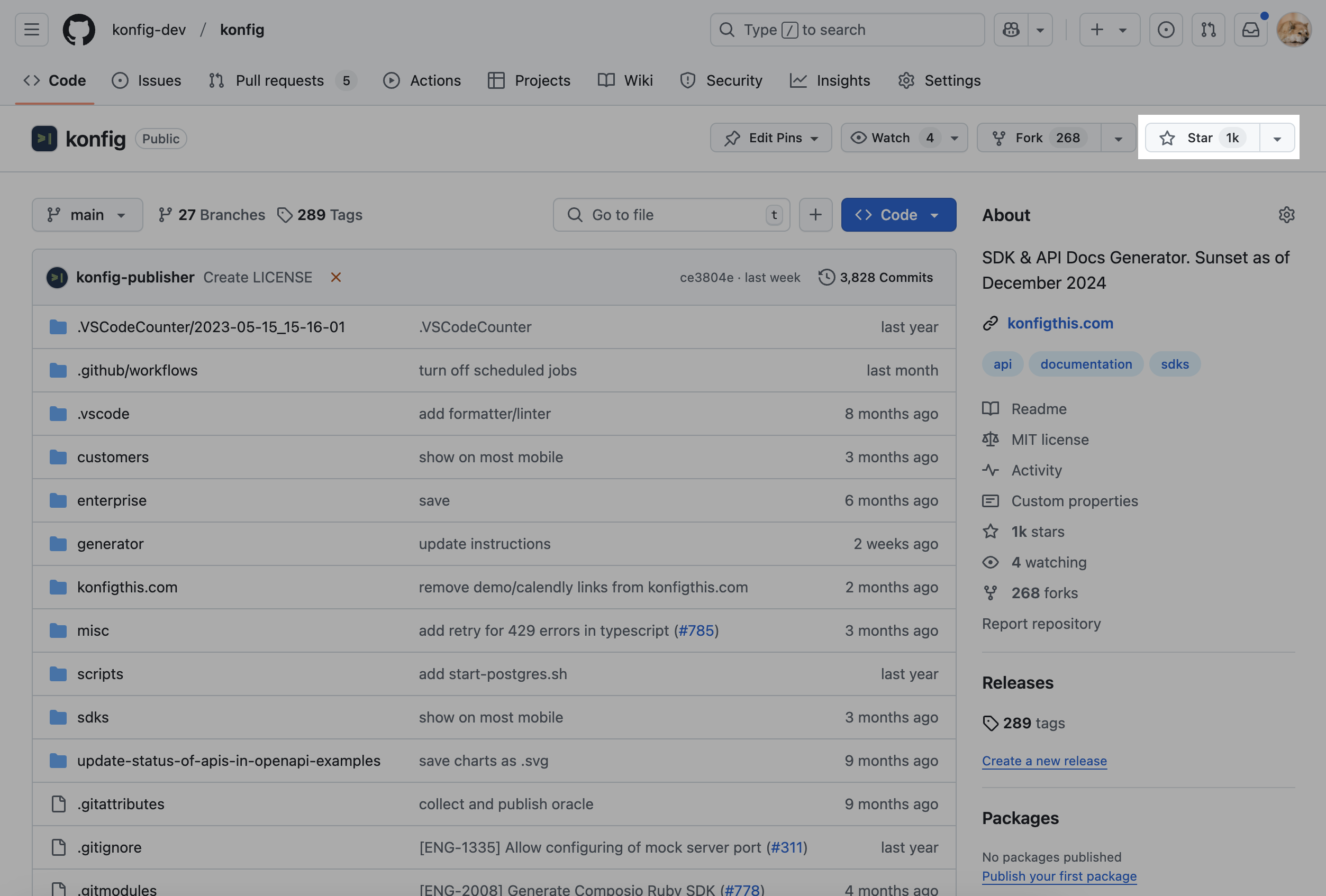
Stars on GitHub:
Screenshot of open source GitHub repo for my startup taken on 12-23-2024
While betting on myself didn't work out financially, the overwhelming response
to sharing my journey has given me a unique sense of validation I've never felt
before in my career. The way my story resonated with the tech community—from
complete strangers to old colleagues—tells me that the skills and experiences I
gained over these 3 years are genuinely valuable. Sure, it's just social
validation, but seeing my post hit the front page of Hacker News and
/r/programming suggests that my experience building and shutting down a startup
resonates deeply with other engineers. When I look at my refreshed resume now, I
see more than just another failed startup—I recall the experience of shipping
products, pivoting through market changes, and learning hard lessons about what
it takes to build something from scratch. In hindsight, what felt like an ending
when we decided to shut down might just be another stepping stone in my career.
Resume creation is often overcomplicated with clunky word processors and
inflexible templates. After 6 years away from the job market (see
why), I needed to create a new resume and faced a
crucial system design decision: stick with traditional tools like Microsoft
Word, or leverage my software engineering experience to build something more
robust and portable. I chose to create a solution that is:
Easy to maintain and version controllable with Git.
Does not require messing around with clunky word processing software.
Lets me just put my content to file without thinking about any of the formatting.
After a couple years of blog and documentation content creation, I've never
found something more simple yet flexible as markdown for authoring
content. The separation of content and styling that markdown provides means that
once you figure out the formatting once, you never have to think about it again—you can just focus on writing great content. Previously I've built my resume
using LaTeX and a template (ifykyk),
but after looking back at the source for that resume, I just don't want to dive
back into writing LaTeX. It's great, but not nearly as simple as Markdown. I did
a quick Perplexity
search
which led me to a GitHub repo
showing how to use pandoc to convert Markdown to HTML.
Then you can use one of many HTML to PDF tools along with your own custom .css
file to produce a final PDF. The best part is that you can use CSS to style
every aspect of your resume—from fonts and colors to layout and spacing—giving you complete control over the visual presentation while keeping the
content in simple Markdown.
The entire workflow consists of one shell script to run two commands.
generate-pdf.sh
#!/bin/sh # Generate HTML first pandoc resume.md -f markdown -t html -c resume-stylesheet.css -s -o resume.html # Use puppeteer to convert HTML to PDF node generate-pdf.js
Here is the JavaScript to kick off a headless puppeteer browser to export the
HTML to PDF. I chose puppeteer over alternatives like wkhtmltopdf and weasyprint
because neither properly respected the CSS I wrote—specifically trying to
style the role/company/dates line in the experiences section to be in a single
yet evenly spaced row was not possible with wkhtmltopdf, and weasyprint's output
styling did not match my CSS either.
Check out the output here and the source markdown
here.
You can also check out the custom .css file I used
here,
it's simple and classic. I tried not to stray too far away from traditional
resume styling but added a little bit of fundamentals from Refactoring UI,
primarily about visual hierarchy and spacing.
And by "all," I mean everything: core product, failed pivots, miscellaneous
scripts, deployment configurations, marketing website, and more. Hopefully the
codebase is interesting or potentially helpful to somebody out there!
Konfig was a developer tools startup focused on making API integrations easier.
We started in late 2022 with the mission of simplifying how developers work with
APIs by providing better tooling around SDK generation, documentation, and
testing.
Our main product was an SDK Generator that could take any OpenAPI specification
and generate high-quality client libraries in multiple programming languages. We
expanded this with additional tools for API documentation and interactive API
testing environments.
While we gained some traction with some startups, we ultimately weren't able to
build a hyper-growth business. It was too difficult to get potential customers to
sign contracts with us and that price points were too low despite the
demonstrably ROI. We then decided to pivot into a vertical B2B SaaS AI product
because we felt we could use the breakthroughs in Gen AI to solve previously
unsolvable problems, but after going through user interviews and the sales cycle
for many different ideas, we haven't been able to find enough traction to make
us believe that we were on the right track to build a huge business.
Despite the outcome, we're proud of the technology we built and believe our work
could be helpful for others. That's why we're open-sourcing our entire codebase.
Here is the public GitHub repo. I'm releasing it exactly as it was when we shut down—no cleanup, no polishing, no modifications. This is our startup's codebase in its true, unfiltered form.
The Konfig GitHub repository containing all our startup's code: the good, the bad, and the ugly.
I want to express my deepest gratitude to everyone who supported us on this
journey. To our investors who believed in our vision and backed us financially,
thank you for taking a chance on us. To our customers who trusted us with their
business and provided invaluable feedback, you helped shape our products and
understanding of the market. And to Eddie and Anh-Tuan, my incredible
teammates—thank you for your dedication, hard work, and partnership through all
the ups and downs. Your contributions made this startup journey not just
possible, but truly meaningful and worthwhile.
Looking back to March 2022 when I left my job to pursue this startup full-time,
I have absolutely no regrets. I knew the risks—that failure was a very real
possibility—but I also knew I had to take this chance. Today, even as we close
this chapter, I'm grateful for the failure because it has taught me more than
success ever could. The experience has been transformative, showing me what I'm
capable of and what I still need to learn.
As for what's next, I'm excited to explore new opportunities, see where the job
market thinks I fit (haha), and continue learning and growing. Who knows? Maybe
someday I'll take another shot at building something of my own. But for now, I'm
thankful for the journey, the lessons learned, and the relationships built. This
experience has been invaluable, and I'm grateful for everyone involved.
Many startups are racing to find product-market fit at the intersection of AI
and various industries. Several successful use-cases have already emerged,
including coding assistants (Cursor), marketing copy
(Jasper), search
(Perplexity), real estate
(Elise), and RFPs (GovDash).
While there are likely other successful LLM applications out there, these are
the ones I'm familiar with off the top of my head. Through my experience
building and selling LLM tools, I've discovered a new important criteria for
evaluating an idea.
Are LLMs Especially Good at Solving This Problem?
Traditional business advice emphasizes finding and solving urgent, critical
problems. While this principle remains valid, not all pressing problems are
well-suited for LLM solutions, given their current capabilities and limitations.
As non-deterministic algorithms, LLMs cannot be tested with the same rigor as
traditional software. During controlled product demos, LLMs may appear to handle
use-cases flawlessly, creating an illusion of broader applicability. However,
when deployed to production environments with diverse, unpredictable inputs,
carefully crafted prompts often fail to maintain consistent performance.
However, LLMs can excel when their non-deterministic nature doesn't matter or
even provides benefits. Let's examine successful LLM use-cases where this is
true.
Think of coding assistants like Cursor that help you write code and complete
your lines.
When you code, there's usually a "right way" to solve a problem. Even though
there are many ways to write code, most good solutions look similar—this is what
we call "low entropy", like how recipes for chocolate chip cookies tend to
share common ingredients and steps. LLMs are really good at pattern matching,
which is perfect for coding because writing code is all about recognizing and
applying common patterns. Just like how you might see similar ways to write a
login form or sort a list across different projects, LLMs have learned these
patterns from seeing lots of code, making them great at suggesting the right
solutions.
Marketing copy is more art than science, making non-deterministic LLM outputs
acceptable. Since copywriting involves ideation and iteration rather than
precision, it has a naturally high margin of error.
Search is unique because users don't expect perfect first results - they're used
to scrolling and exploring multiple options on platforms like Google or Amazon.
While search traditionally relies on complex algorithms, LLMs can enhance the
experience by leveraging their ability to synthesize and summarize information
within their context window. This enables a hybrid approach where traditional
search algorithms surface results that LLMs can then summarize to guide users to
what they're looking for.
Leasing agents primarily answer questions about properties to help renters find
suitable homes and sign leases. Since their core function involves retrieving
and relaying property information, a real estate assistant effectively becomes
a specialized search problem.
RFP responses combine two LLM strengths: extracting questions from lengthy,
unstructured documents and searching internal knowledge bases for relevant
answers. Since extracting questions from RFPs is time-consuming but
straightforward, LLMs can work in parallel to identify all requirements that
need addressing. This makes the RFP response process essentially a document
extraction and search problem that's perfect for automation.
When building an LLM startup, focus on problems with two key characteristics:
Low Entropy - solutions follow common patterns, as seen in coding
High margin of error - tasks like copywriting where art trumps science
Or can be solved in a similar way to common well-suited problem types such as:
Search
Document extraction
Beyond traditional business evaluation, ask yourself: "Are LLMs particularly
well-suited to solve this problem?" If not, reconsider unless you have unique
insights into making it work.
Screenshot of a workflow on our self-hosted Dify instance
To be clear, Dify is one of the most capable, well-designed,
and useful prompt engineering tools I have used to date. I've tried code-only solutions
such as LangChain and other no-code tools such as LangFlow, but Dify currently takes
the cake. I've also briefly tried others such as PromptLayer, but when it comes
to building agentic workflows,
which I believe is the future of AI automation, Dify feels like a better fit. In
particular, I appreciate its great UI design, workflow editor, and self-hosting
option. But there is always room for improvement. Here are the things I would
improve about dify.ai today.
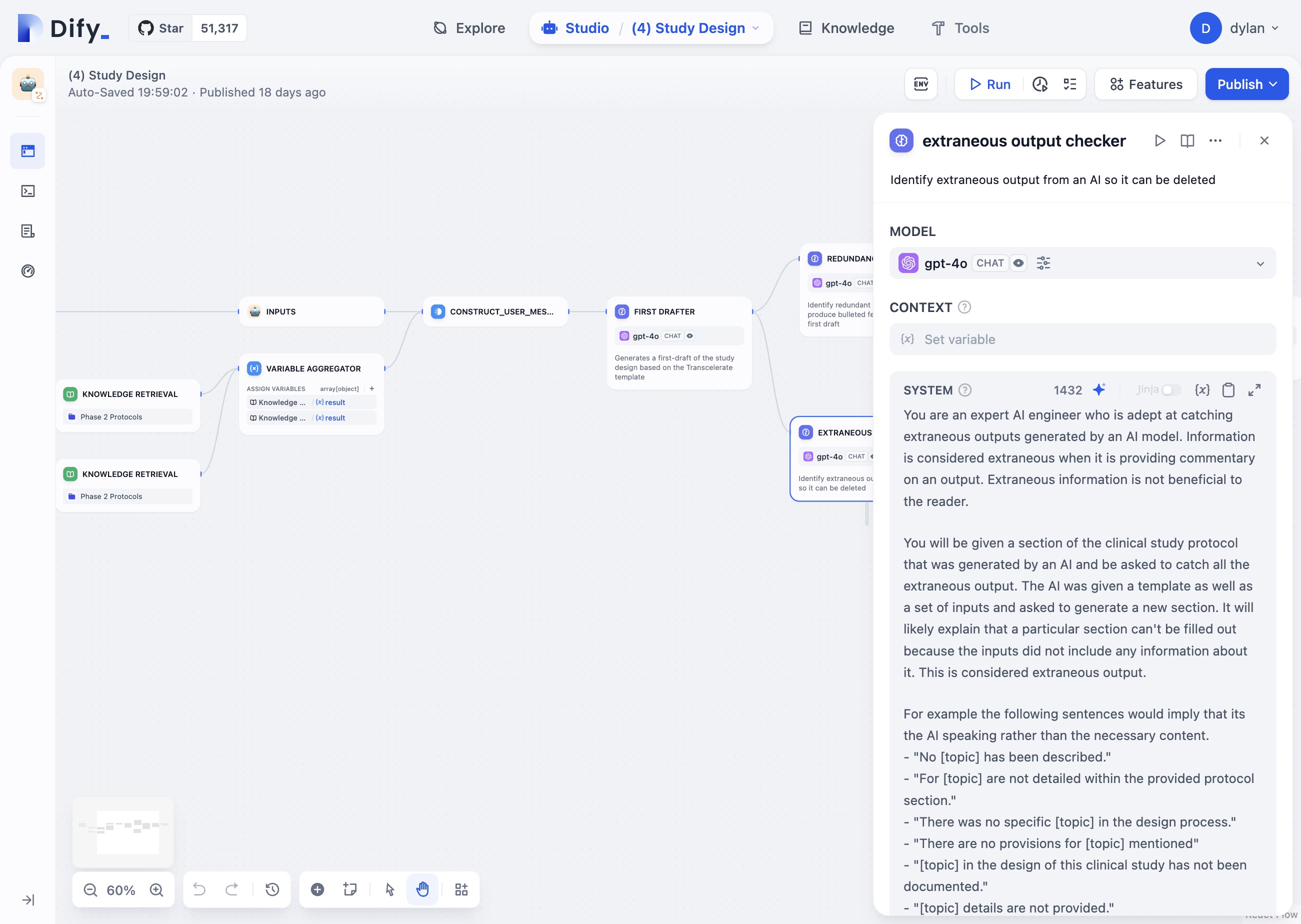
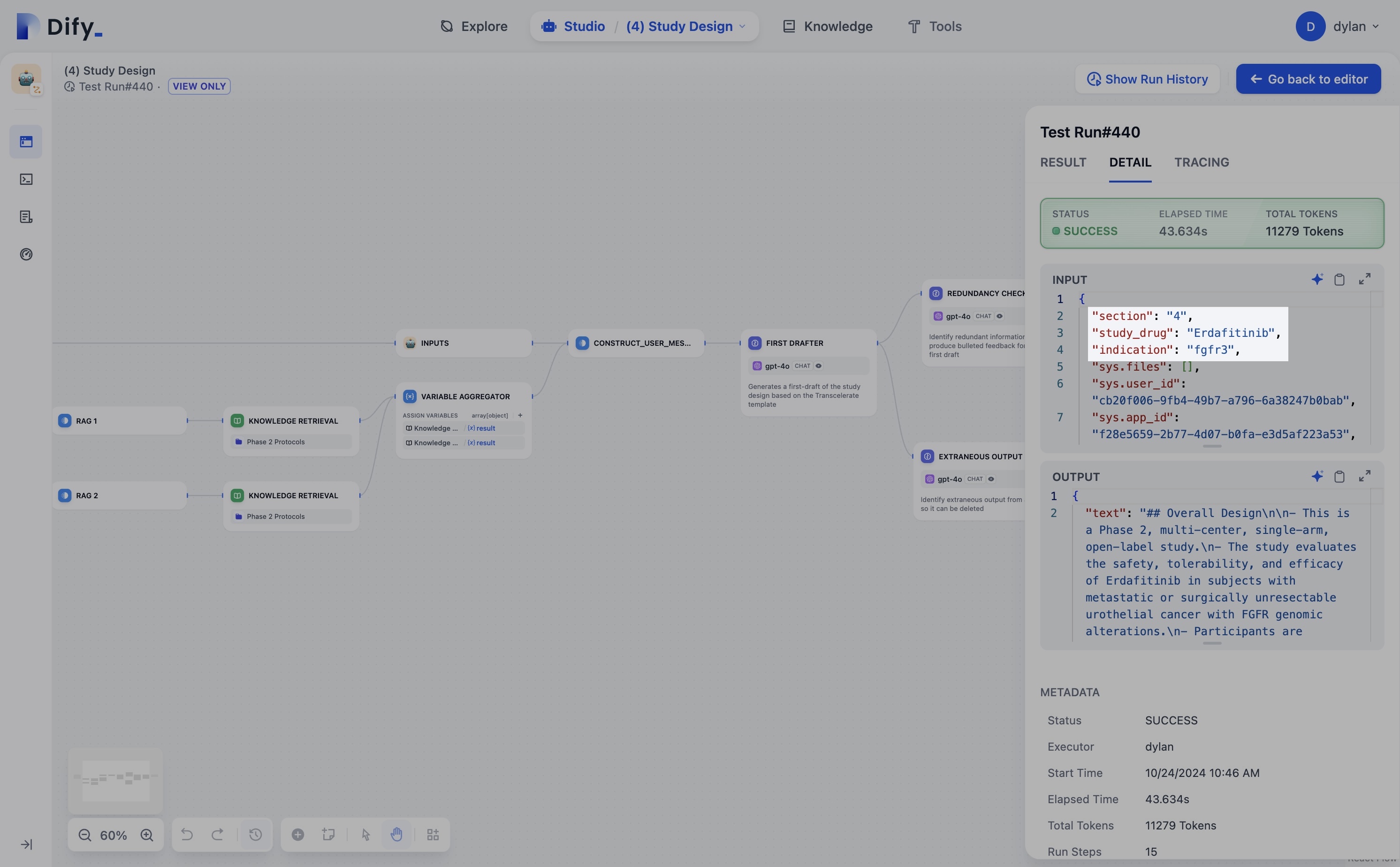
When testing workflows from the studio, it would be really nice to be able to select
inputs from previous runs to be used as inputs for testing.
It would be really nice to just have a button that copies the highlighted inputs (as pictured) from a previous run into a new run
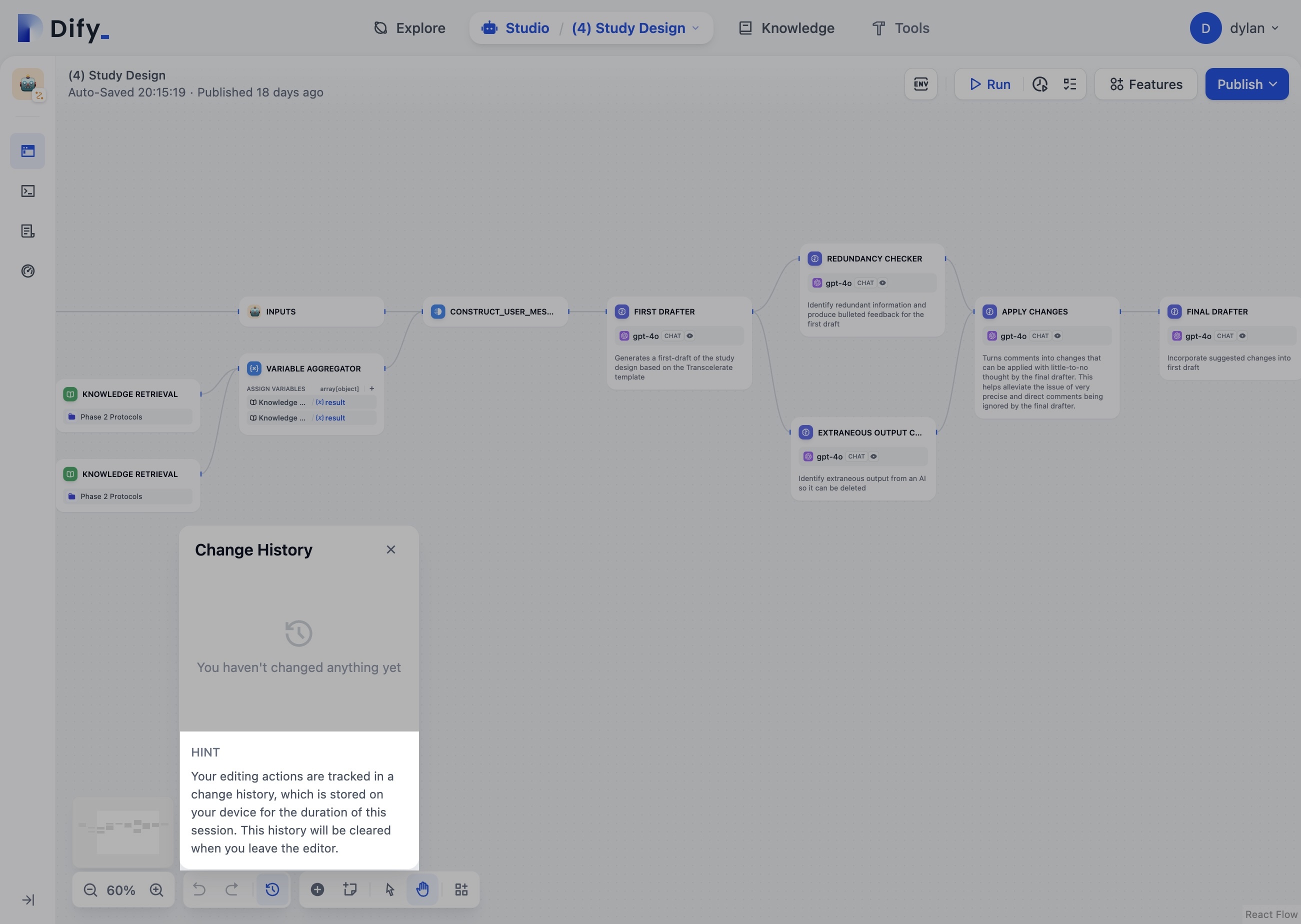
Versions of a workflow should persist on the server. Right now, I'm scared to
close a tab since I'll lose any previous versions of the workflow I'm working
on. If I am making experimental changes, this can be devastating if I don't
remember how the workflow previously worked.
Right now, Dify persists versions in the browser so it's lost when the tab is closed. Dify even explains that your work will be lost when leaving the editor.
When testing changes to a workflow, I would love to have a version of a
workflow that could be published for testing so production remains untouched. It would be even better if it somehow integrated with CI platforms so you could have a team of developers working on their own version of the workflow. This would eventually mean you'd need some sort of integration with Git so you can branch, push, and test changes to the workflow. On that note, it would also be great to be able to author Dify workflows as code, and have that bi-directionally sync with the UI version of Dify. This would be amazing for non-developers and developers to collaborate on agentic workflows.
Right now, you can only publish one version of a workflow to be accessed by API. It would be ideal to instead publish multiple versions for testing and allow the API to route across different versions to be used in local testing or even CI environments
Managing many workflows can be extremely confusing, especially when you clone
a workflow for testing, which could be fixed by adding support for (3). Also, the tile view is not a compact and easy way to scan all the workflows. It would be really nice if there were a table view that could be sorted, searched, filtered, etc.
The current studio view shows workflows as tiles with basic tag filtering. This can get messy and hard to navigate as the number of workflows grows, especially when workflows are cloned for testing. A table view with more robust filtering and sorting would make it much easier to manage.
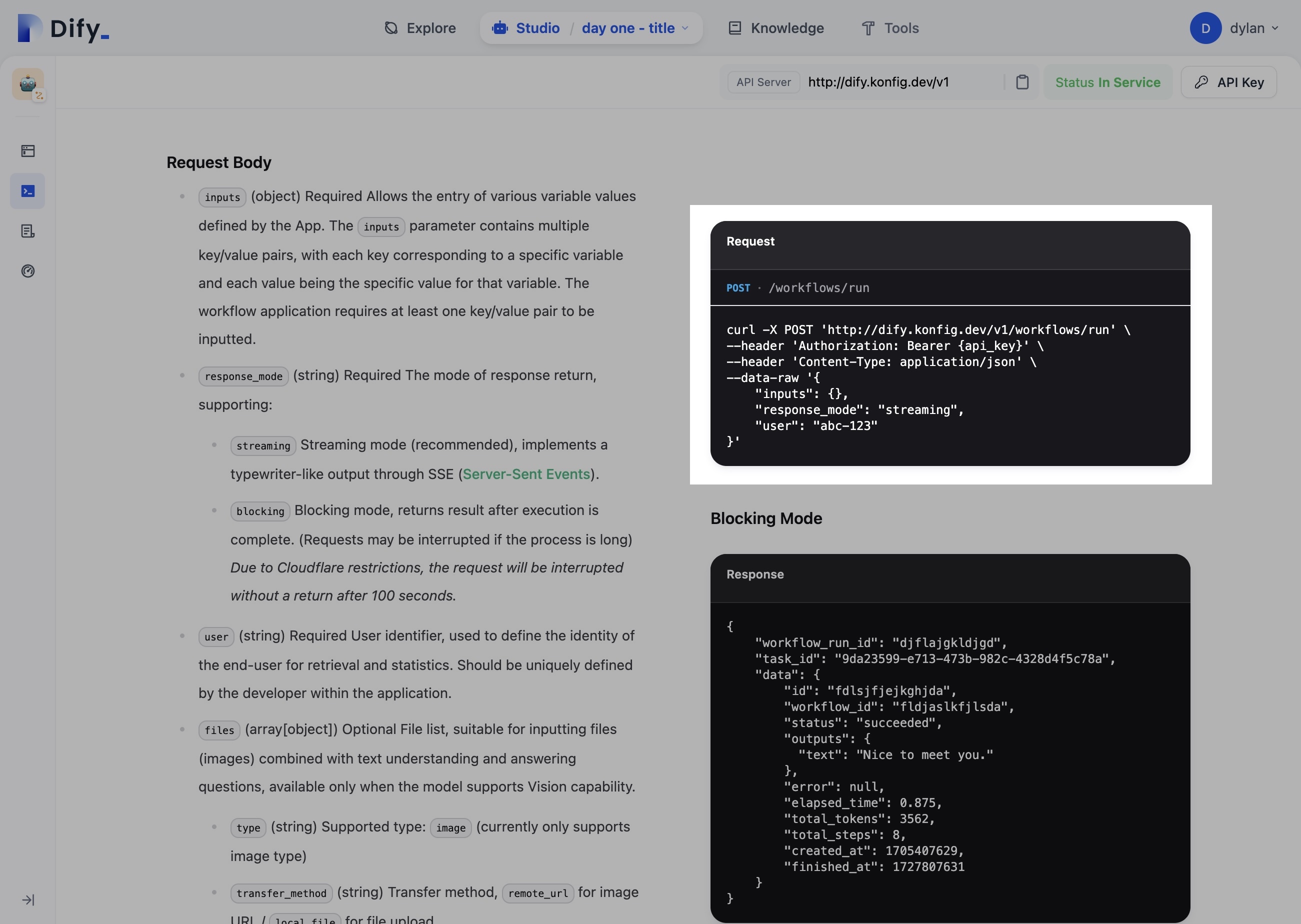
Generated API documentation for the workflow would be nice to save time when integrating a workflow into a codebase.
Currently, Dify provides some static code examples that don't update based on your workflow's inputs and outputs. Having dynamically generated API documentation would make it much easier to integrate workflows into applications.
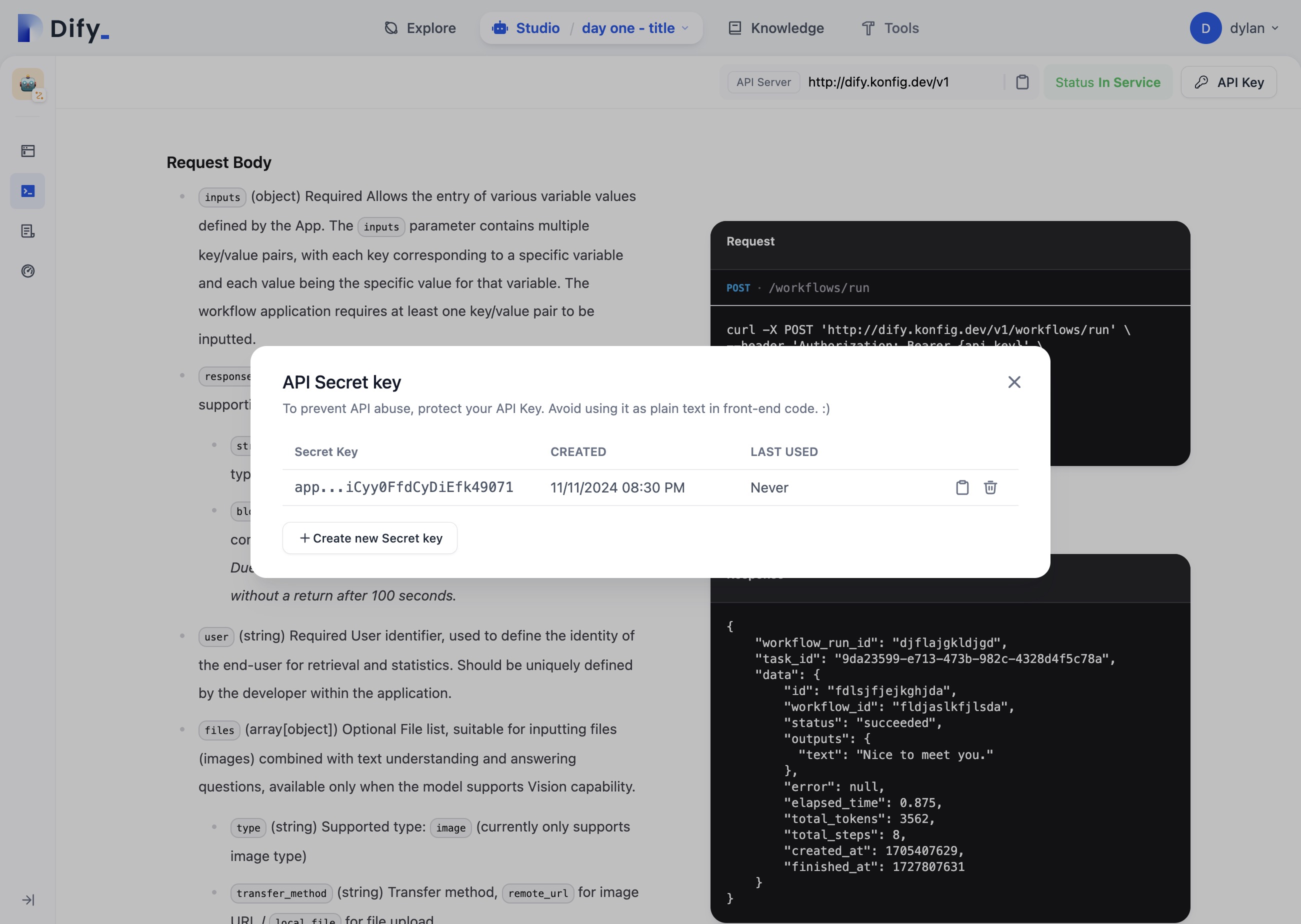
API Keys are extremely annoying to handle when you have many workflows.
Currently, you need to create a separate API key for each workflow, which becomes extremely messy when managing 10+ workflows since keys aren't easily identifiable as belonging to specific workflows. Having a single master API key with workflow identifiers in the API calls would be much simpler to manage and organize.
Overall, there's a lot of room for improvement in Dify.ai, but it's important to remember that it's still in beta. The platform already offers an impressive set of features and a unique approach to building LLM-powered applications. I'm confident that many of these pain points will be addressed as the platform matures.
Some of these suggestions, particularly the bi-directional sync between code and UI, would be technically challenging to implement. However, features like this would significantly differentiate Dify from its competitors and create a truly unique development experience that bridges the gap between technical and non-technical users.
If these improvements were implemented, particularly around version control, testing workflows, and API management, it would dramatically improve the developer experience and make Dify an even more compelling platform for building production-grade AI applications. The potential is already there - these enhancements would just help unlock it further.
In a nutshell, you can implement a button that replaces the entire button with an HTTP response using HTML attributes:
<scriptsrc="https://unpkg.com/[email protected]"></script> <!-- have a button POST a click via AJAX --> <buttonhx-post="/clicked"hx-swap="outerHTML"> Click Me </button>
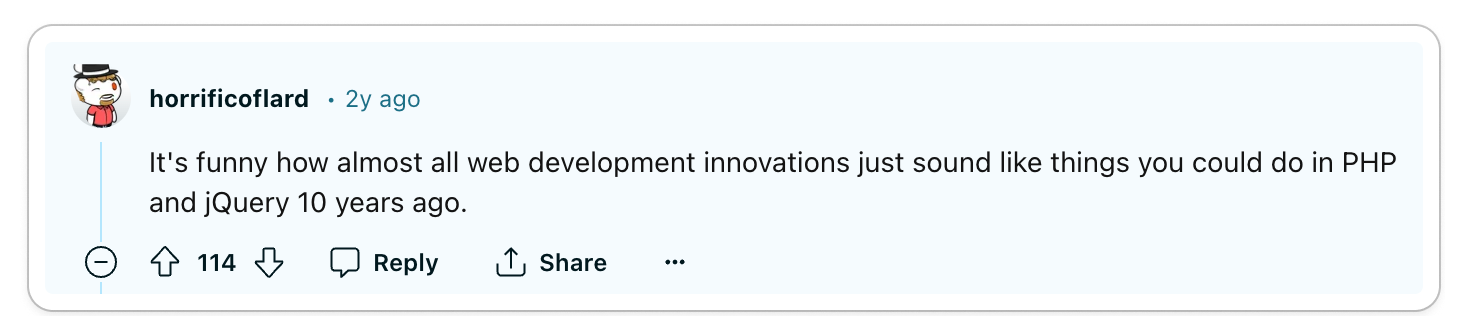
If you follow popular web development trends or are a fan of popular
developer-focused content creators, you have probably heard about it through
Fireship or
ThePrimeagen. However, HTMX has
brought an absolute whirlwind of controversy with its radically different
approach to building user interfaces. Some folks are skeptical, others are
excited, and others are just curious.
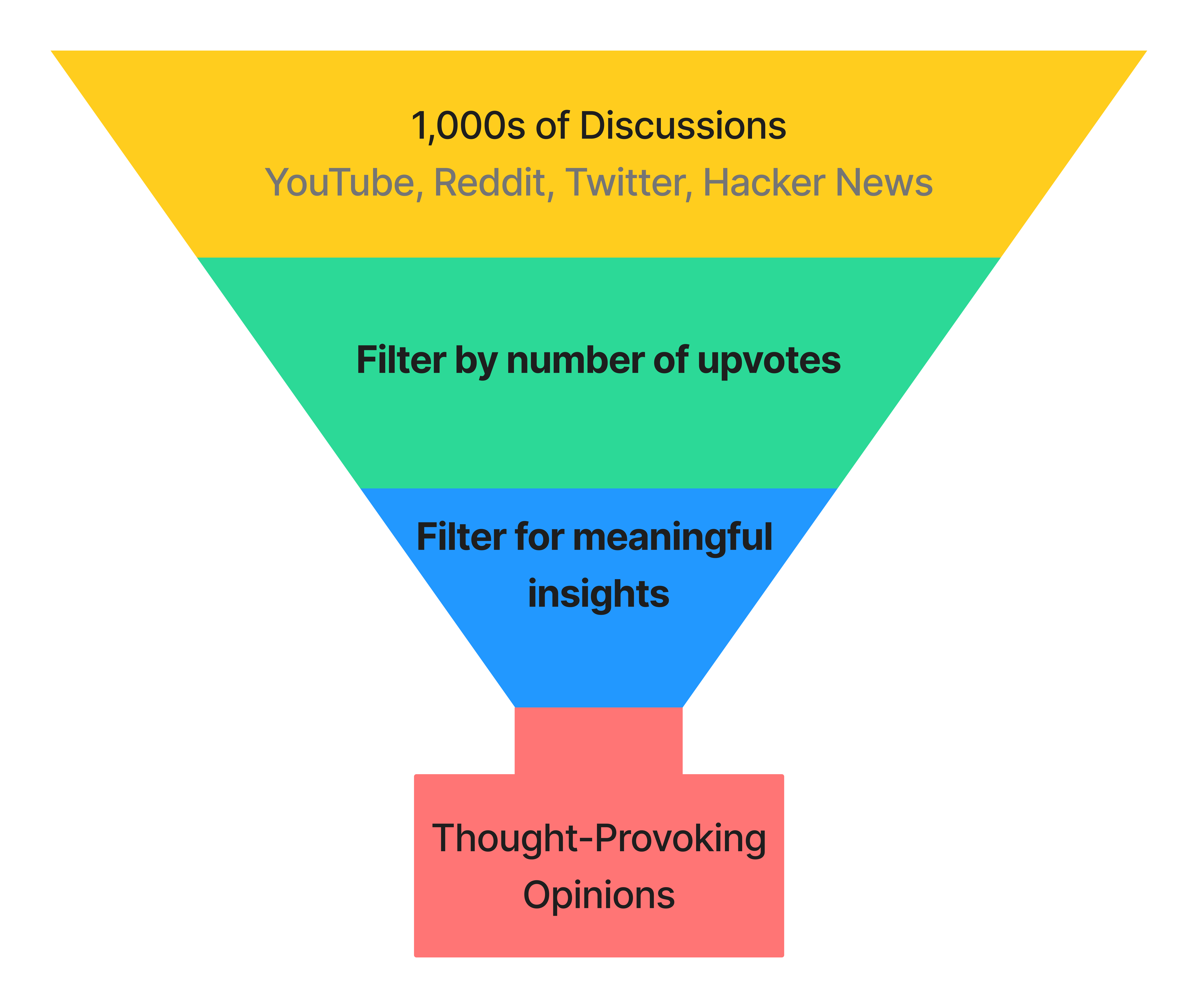
To analyze how developers truly feel about HTMX, I went to where developers
live: Reddit, Twitter, Hacker News, and YouTube. I parsed 1,000s of discussions
and synthesized my findings in this article, striving to present only
thought-provoking opinions.
Funnel for gathering through-provoking opinions
Next, I transcribed these discussions onto a whiteboard, organizing them into
"Pro-HTMX" (👍), "Anti-HTMX" (👎), or "Neutral" (🧐) categories, and then
clustering them into distinct opinions. Each section in this post showcases an
opinion while referencing pertinent discussions.
Whiteboard of opinions
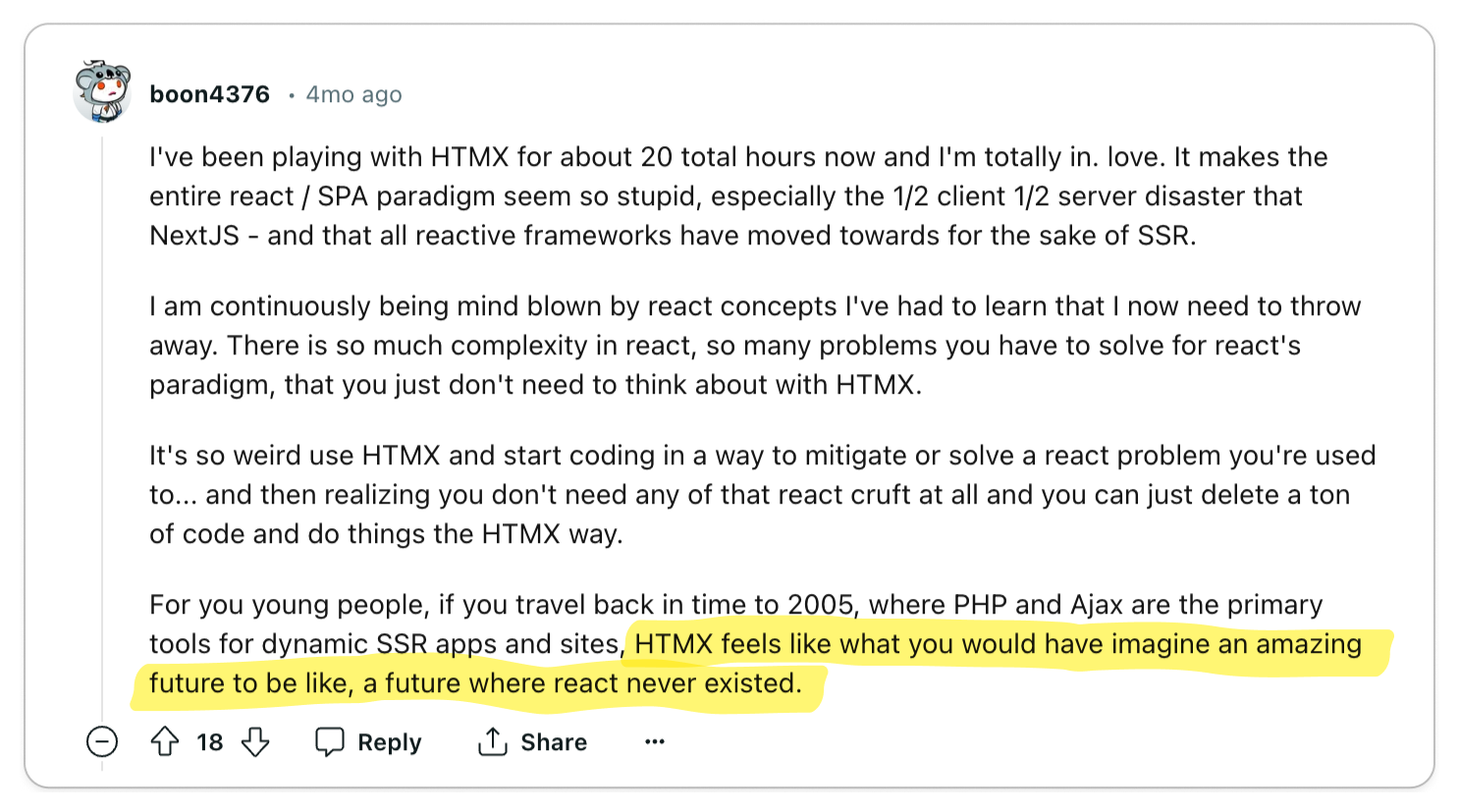
To start, i'll go over the Anti-HTMX (👎) opinions since they are spicy.
After Fireship released a video about
HTMX, HTMX started to gain a lot
of attention for its radical approach to building user interfaces. Carson Gross,
the author of HTMX, is also adept at generating buzz on his
Twitter. And since HTMX is new, its unlikely
that you will find a lot of examples of sufficiently complex applications using
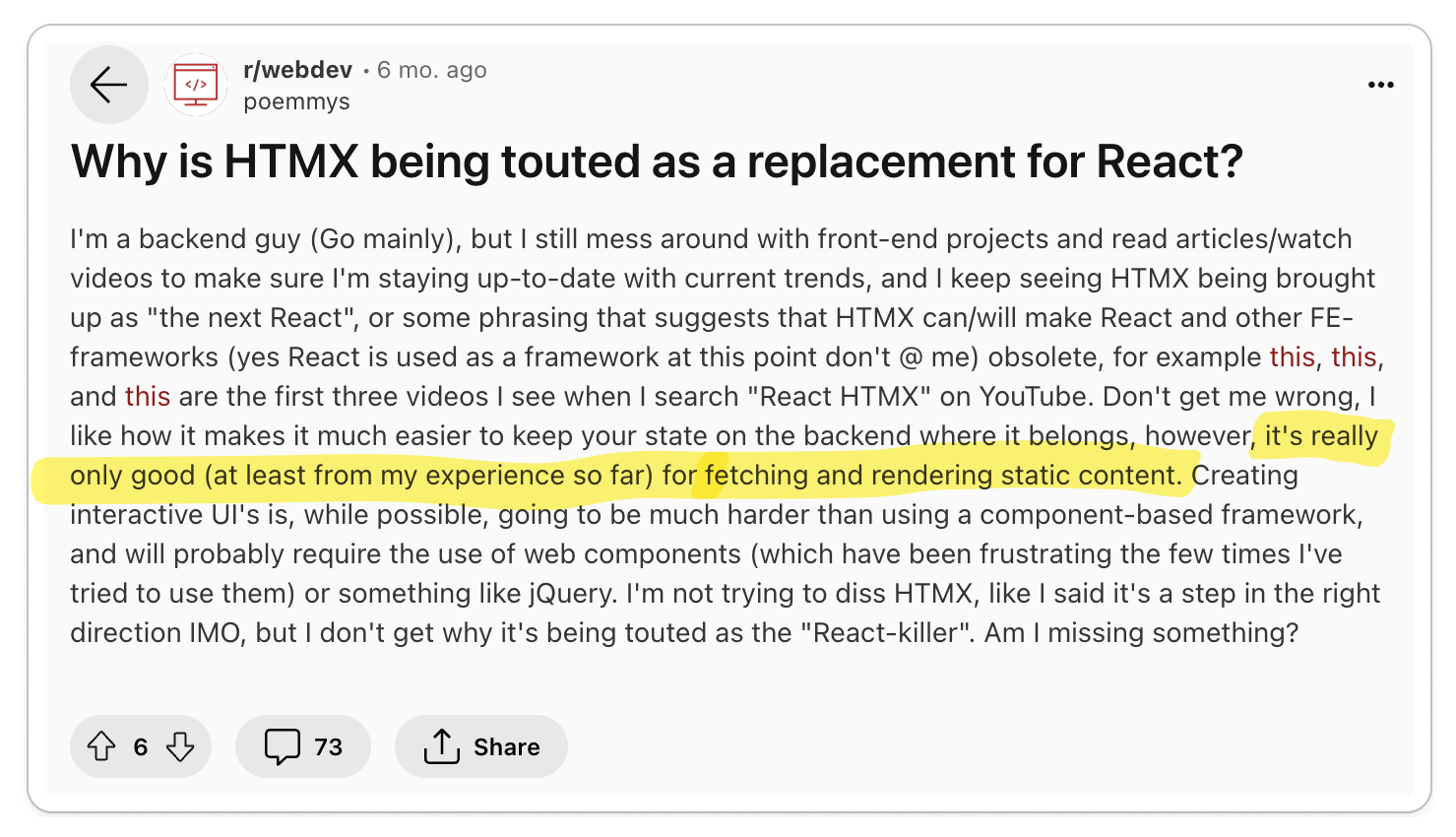
HTMX. Therefore, some developers are of the opinion that HTMX is merely
capitalizing on hype rather than offering a genuine solution to the challenges
of building user interfaces.
Like all technologies, there is typically a cycle of hype, adoption, and
dispersion. HTMX is no different. This cycle is beginning to unfold, and it's
time to see what the future holds. It is fair to criticize HTMX for riding a
wave of hype. However, if developers feel HTMX is solving a real problem
and adopting it accordingly, then adoption will naturally occur. But only time
will tell...
If you squint at HTMX, it looks like a relic of the past where MPA (Multi-page
Applications) were the norm. Some developers see HTMX as a step back, not
forward. There is a good reason why modern web applications are built using
technologies like React, Next.js, and Vue.js. To ignore this, and use HTMX, you
might be ignoring the modern best practices of building web applications.
Depending on your level of expertise in building with modern web technologies,
you may feel that HTMX is a step back, not forward—especially if you have
previously built MPAs with jQuery. For those who see HTMX as a step back, they
want nothing to do with it.
If you are already familiar with modern web technologies, your teammates are as
well, and current applications are using the latest web technologies, it's
really hard to see why you would use HTMX in future applications. But for those
starting new applications, HTMX is simply a different approach to building interfaces.
Whether it is worth considering depends on the complexity of your application's
interface and the expertise of your team. But it definitely doesn't hurt to
entertain new ideas like HTMX. Who knows, it could ultimately improve your
skills as an engineer.
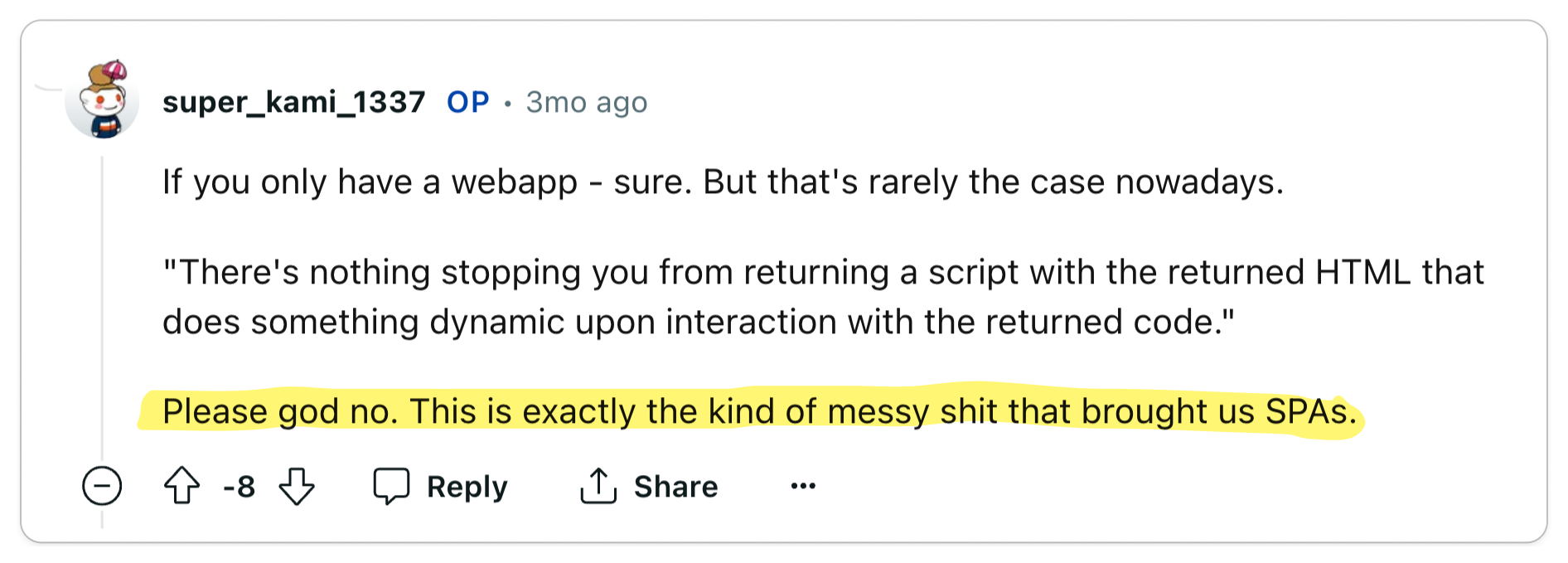
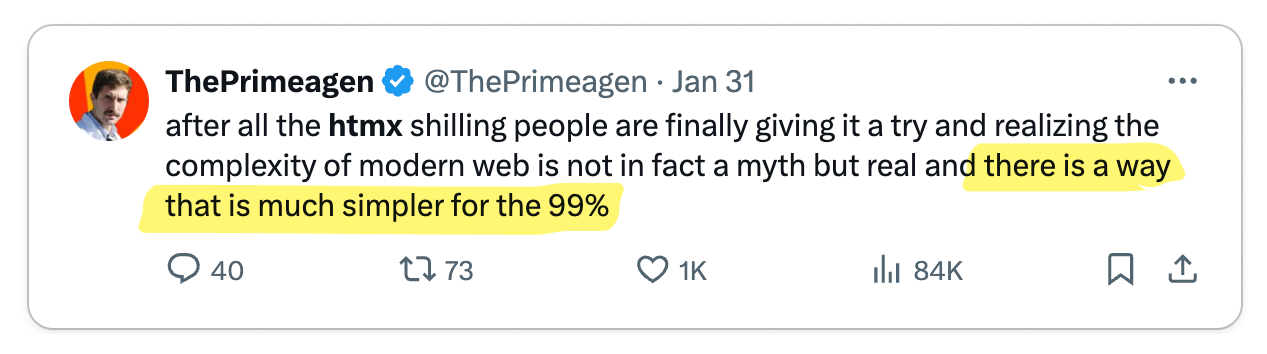
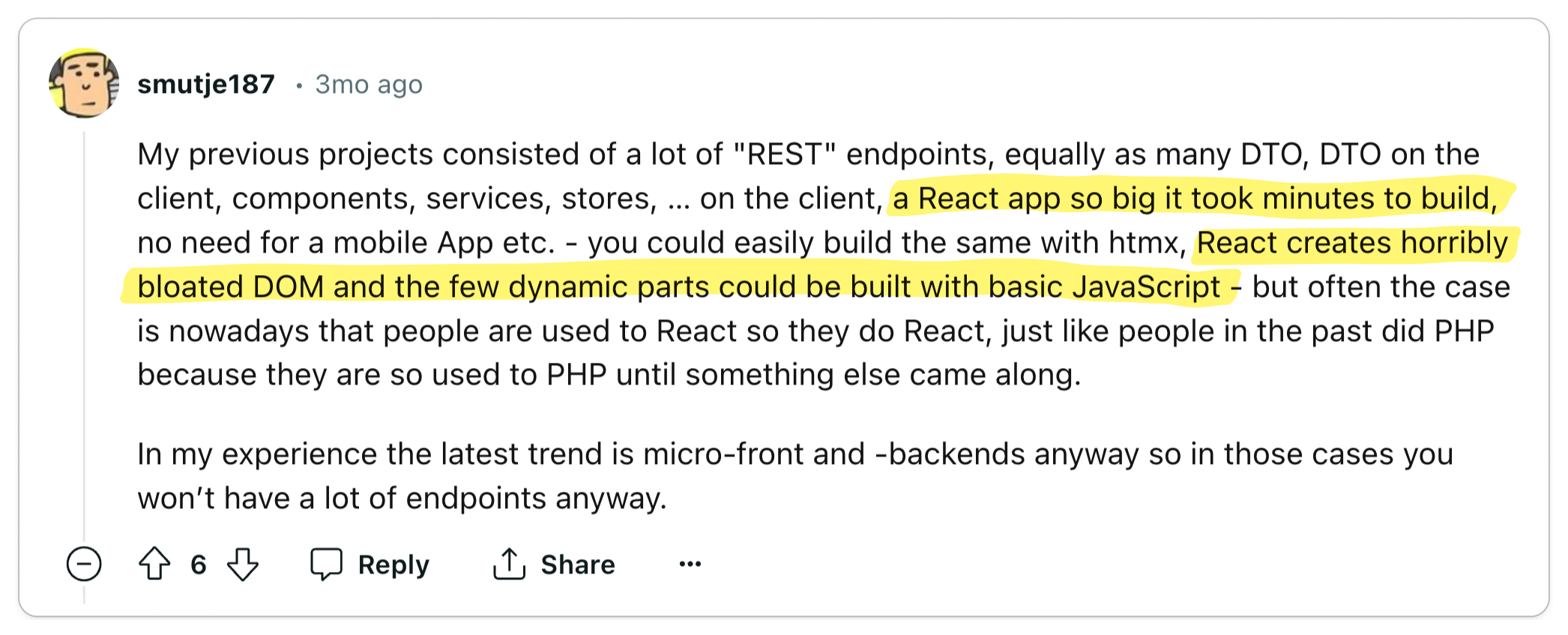
👎 HTMX is unnecessarily complex and less user-friendly
In practice, some developers feel that HTMX is actually more complex than the
current best practices. They specifically dislike the use of HTML attributes,
magic strings, and magic behavior. Moreover, some developers feel this make
engineerings teams less productive and codebases more complex.
People will always have a natural aversion to unfamiliar technologies, and HTMX is
no exception. Those who adopt HTMX in their projects will likely encounter some
friction, which could be a source of frustration and negative discourse. HTMX
also uses more declarative paradigms, which can be harder to read for developers
who are just beginning to learn HTMX. This makes HTMX more complex and less
user-friendly for those sorts of developers.
React involves more in-memory state management on the client, while HTMX, on the
other hand, embeds state in HTML itself. This is a fundamentally new approach to
interface design, which developers would need to learn and adopt before feeling
comfortable reading and programming with HTMX.
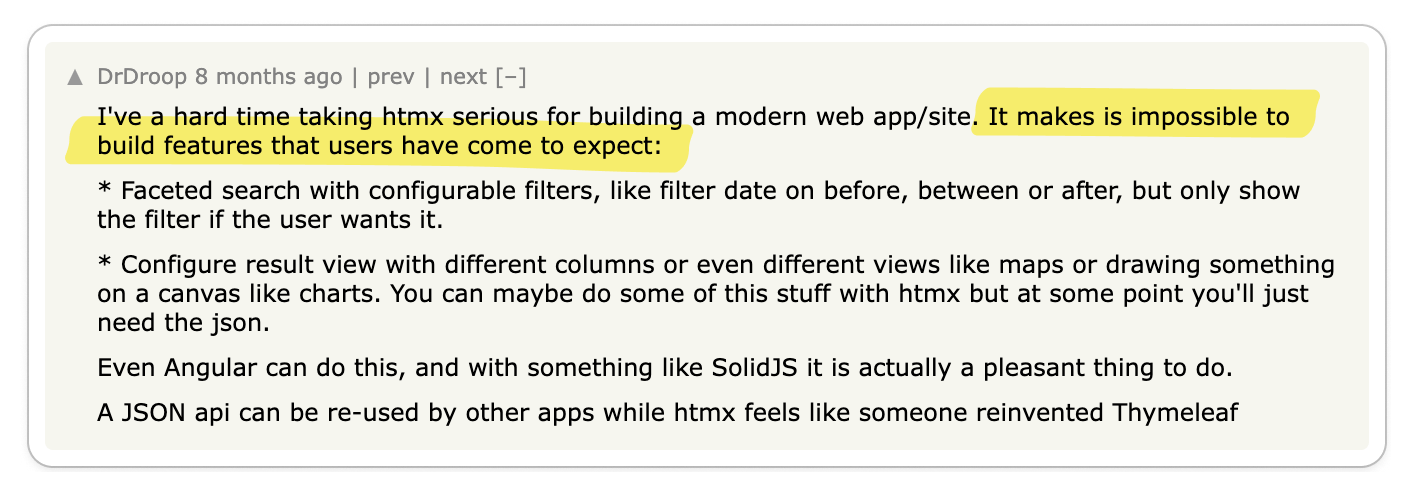
Users expect modern interfaces which require more complex DOM manipulations and
UX design. To implement such interfaces, using HTMX is not enough. Therefore,
HTMX is only good for simple use-cases.
For developers that are working on more complex use-cases, HTMX is not enough.
And since HTMX has sort of compared itself to React, it is fair to point out
that HTMX is not a solution for building complex web applications.
Before deciding to use HTMX, developers should first consider the complexity of
the use-case. If HTMX is not the right tool for the job, then look elsewhere for
libraries that will allow you to solve the problem. It may well be the case that
your use-case will require a "thick client".
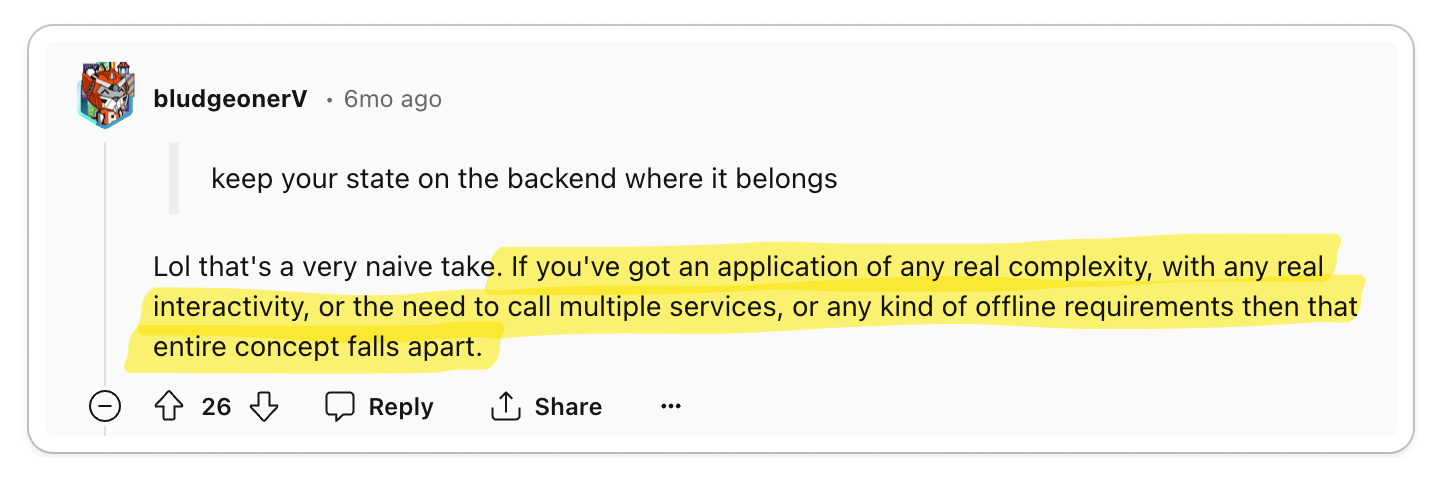
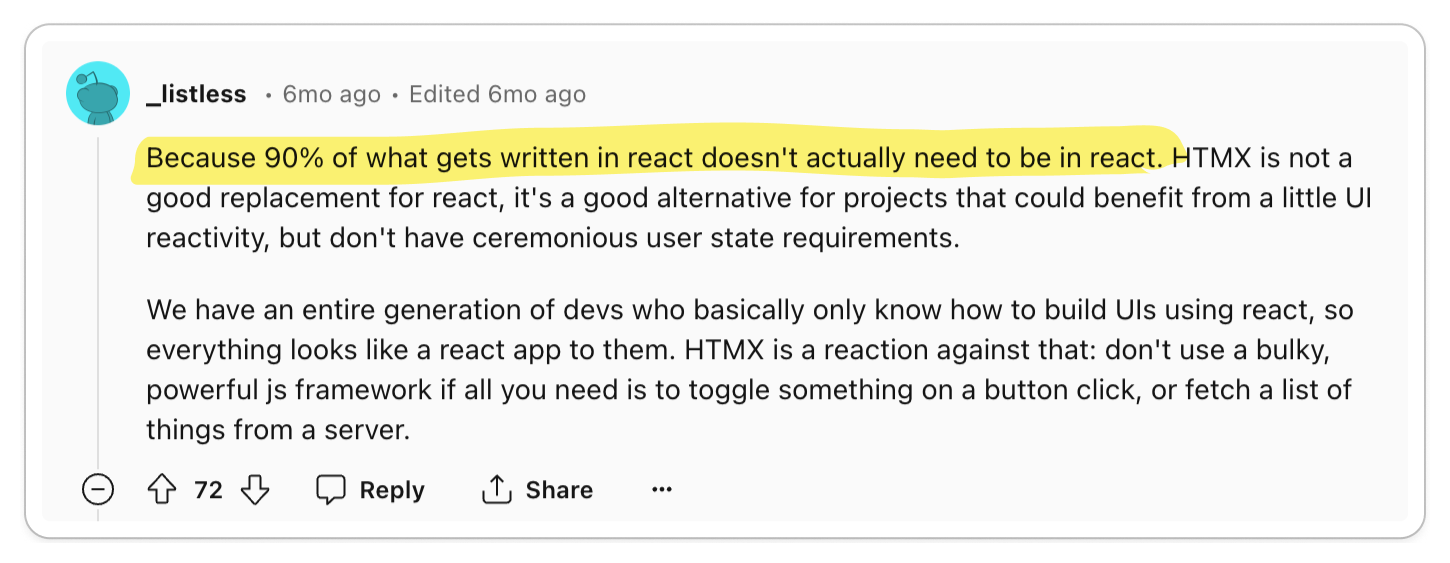
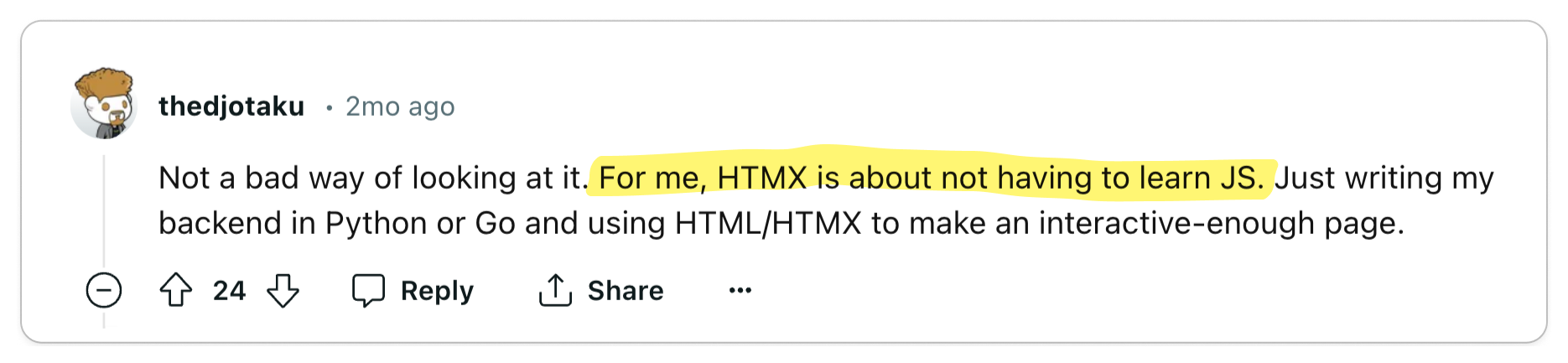
Developers are witnessing a reduction in codebase complexity and a decrease in
overall development time. As grug puts it, "complexity
is bad". Developers who embrace this mindset are highly enthusiastic about HTMX.
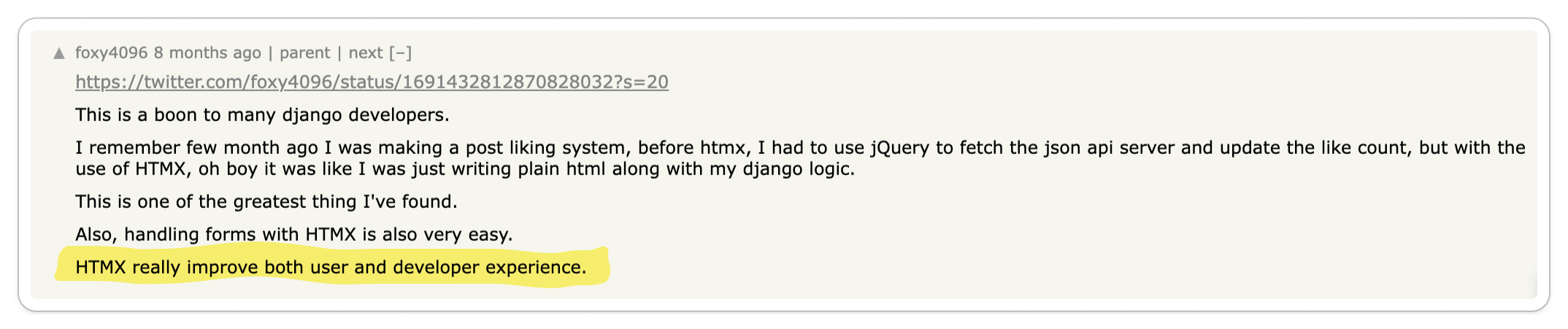
With HTMX handling the DOM manipulations, developers can deduplicate logic from
the browser to the server. This marks a significant improvement over the current
best practices for building web applications, where a lot of logic needs to be
duplicated in the server and client. For backends that are not written in
JavaScript, the current standard UI libraries can be a significant burden on the
developers of the application.
Simplicity is a subjective concept. It highly depends on your application, team,
and use-cases. For those who have spent a lot of time with JavaScript, HTMX
stands out for its simplicity. If you feel that the current best practices are
overbuilt, bloated, and overly complex—HTMX might be worth considering.
In many use-cases where the primary value of the application lies in the
backend, React may not be essential but could still be the optimal choice for
your team, depending on their expertise.
If you are a backend developer, it's unlikely that you know React, JavaScript,
or meta frameworks like Next.js. Full-stack developers, on the other hand, may
find HTMX to be a breath of fresh air in the form of a simple way to build
interfaces. The fact that pretty much any developer can pick up HTMX is a huge
benefit, especially for teams that are not as comfortable with JavaScript.
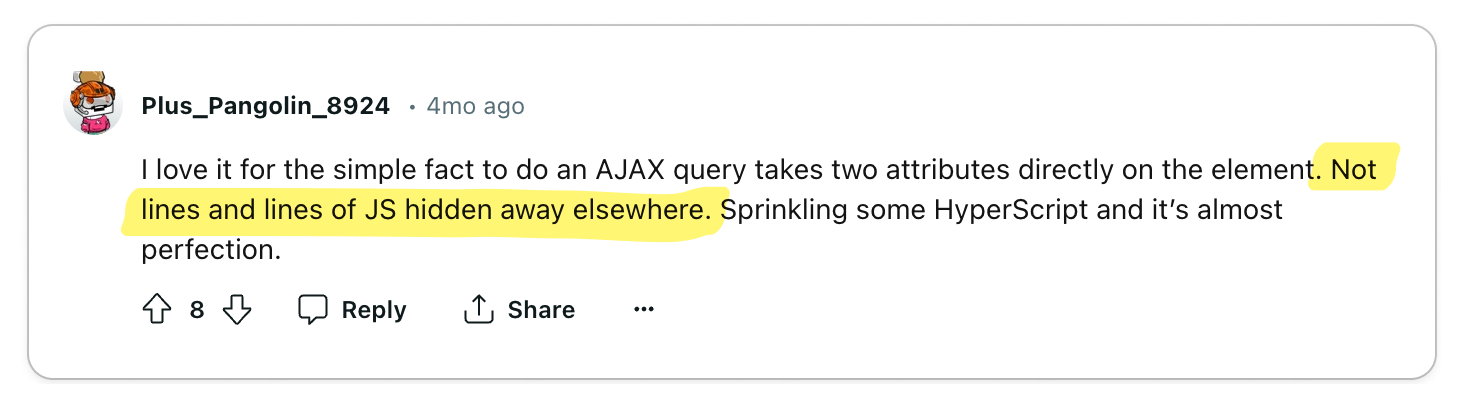
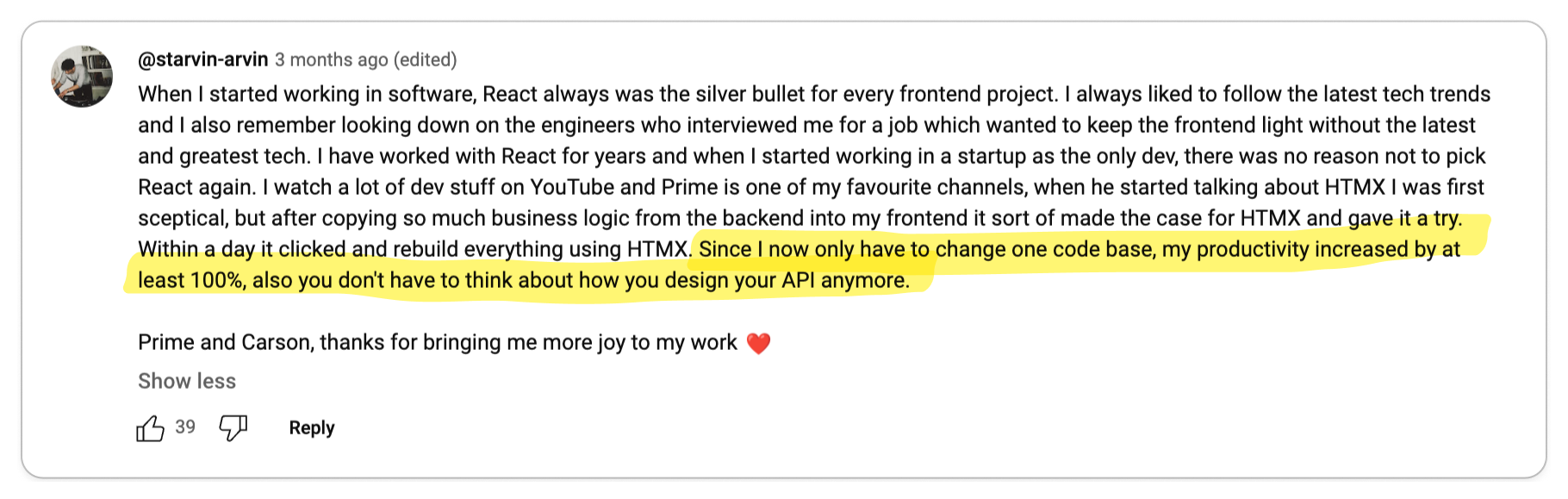
I personally love this perspective and it's actually one of the reasons I've spent
some time experimenting with HTMX. My company is a small team and not all of us
have used React or Next.js, so HTMX as a solution for teams that are not as
comfortable with JavaScript is an extremely compelling narrative for me.
I believe this is true for many other teams as well, especially since full-stack
developers are hard to come by. Some developers are finding that this unlocks
new opportunities for them to work on interesting projects.
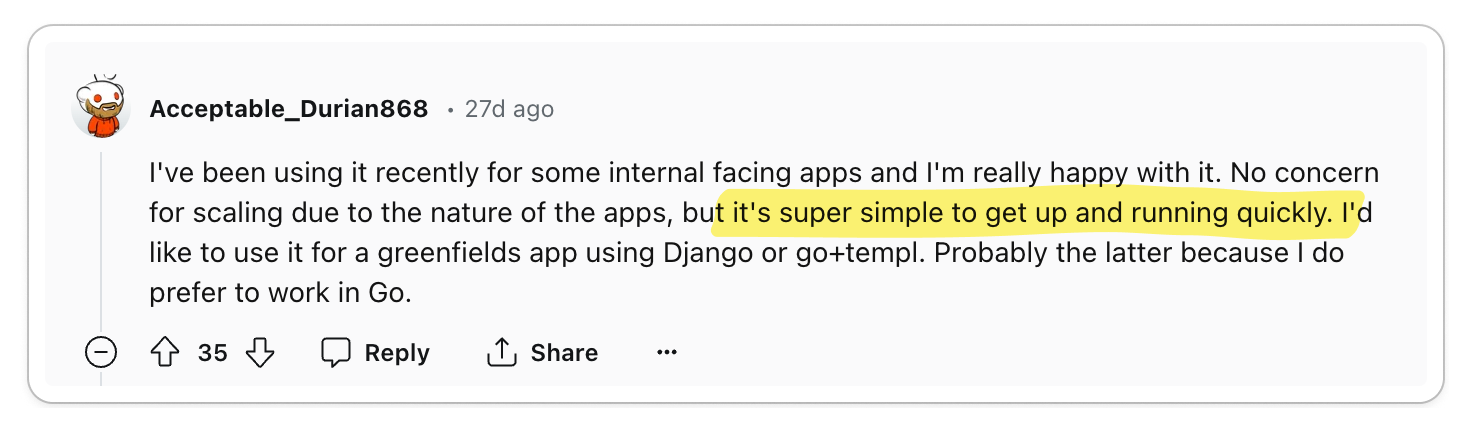
HTMX, when combined with battle-tested templating libraries like Django's
template language or Go's templ library, boosts productivity. By not having to
spend time writing a client-layer for the UI, developers can focus on where the
application is providing most of the value, which is the business logic. This is
especially effective when paired with
By reducing the amount of redundant business logic in the client-layer,
developers are finding that they can focus on the actual product and not the UI.
And since you can get up and running with HTMX with a simple <script> tag, it's
easy to bootstrap a project with HTMX.
These two factors leave a positive impression on the developer experience for
some.
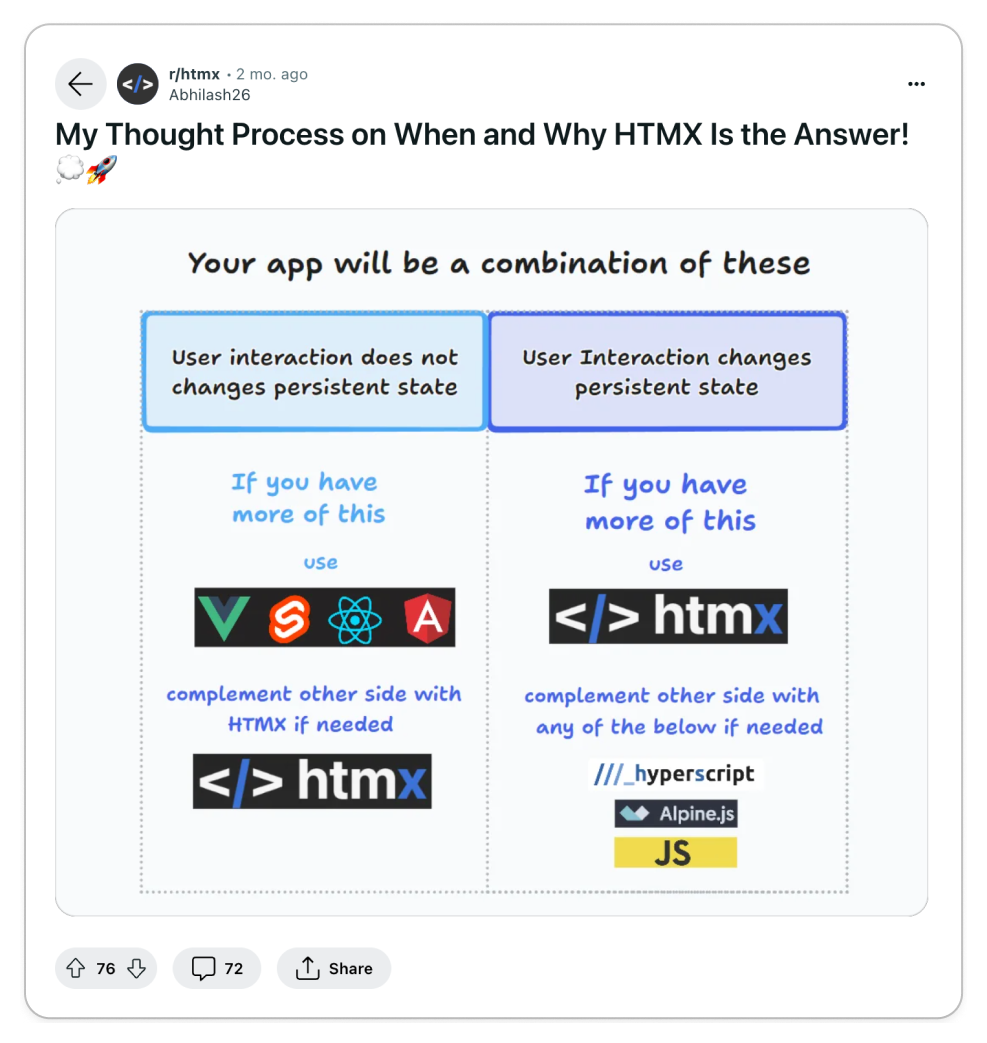
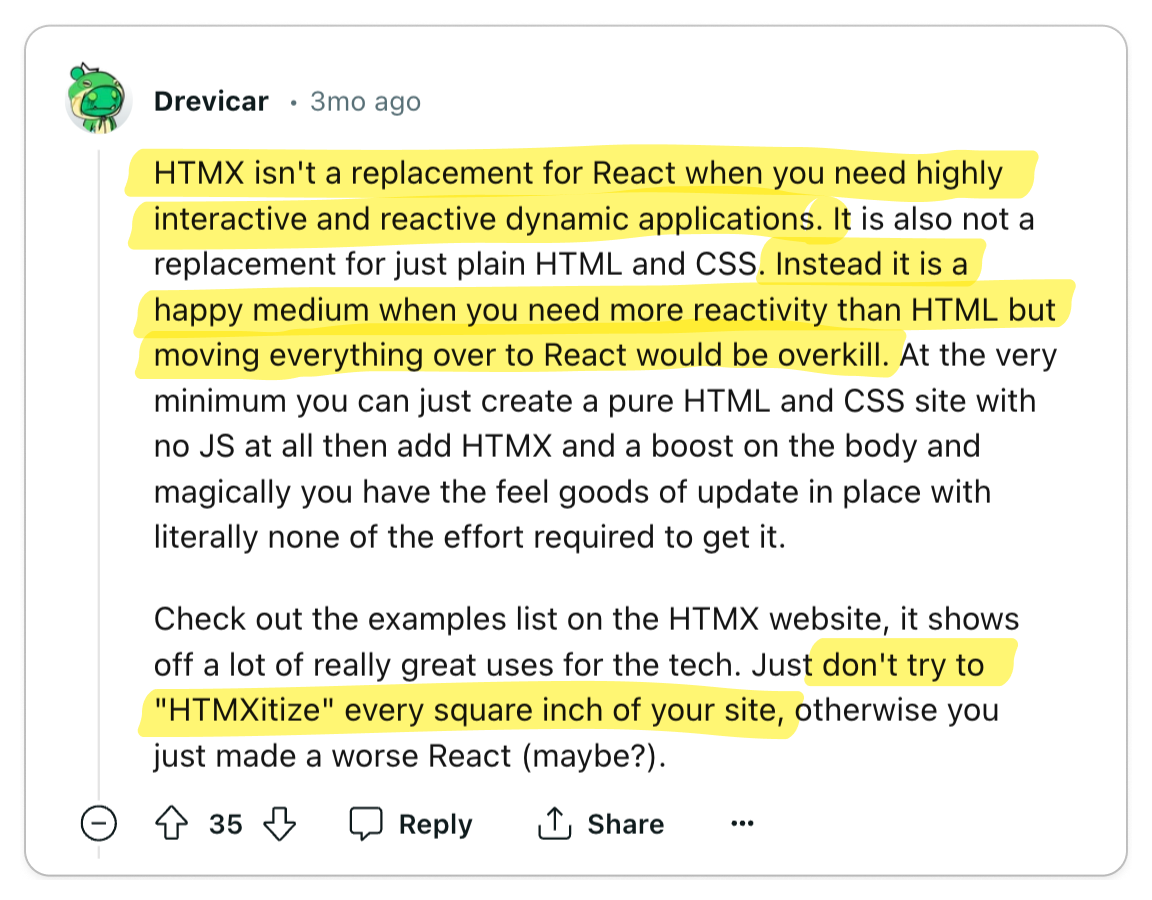
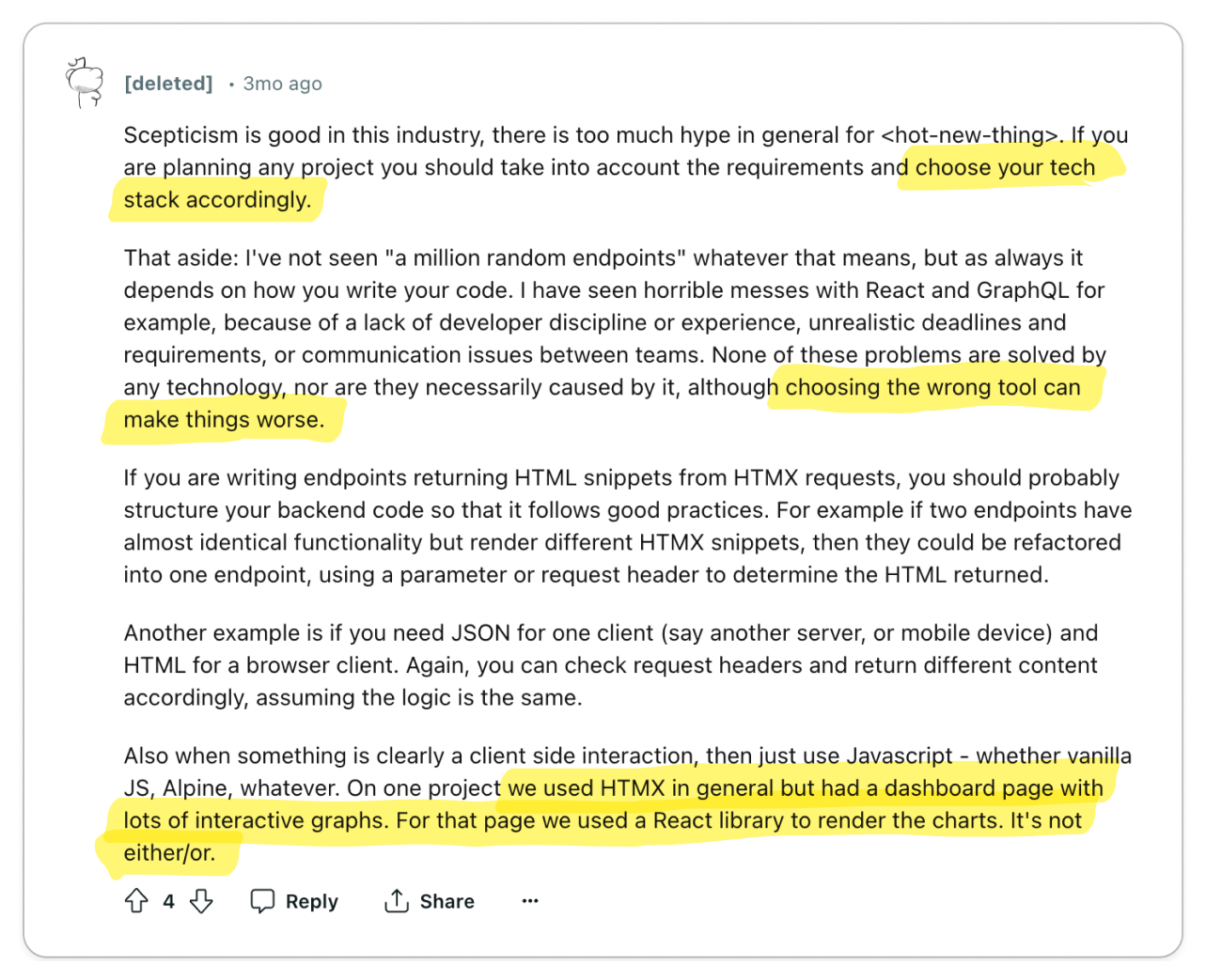
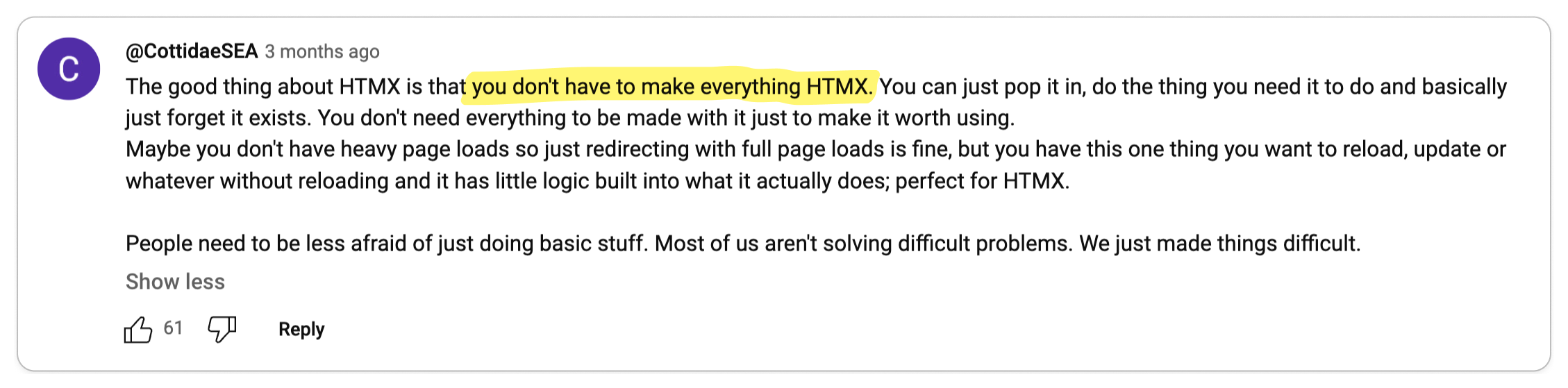
Like any problem, you must choose the right tool for the job. For developers who
see HTMX for its pros and cons, they believe that it's just another tool to
solve a specific problem. And since HTMX can also be progressively adopted,
developers can adopt it in small portions of their codebase. But as always,
certain use-cases will require more complex client logic which would require you
to reach for more advanced tooling like React.
Like everything else in software, choose the right tool for the job. It's not
much of a takeaway, but consider it your responsibility as an engineer to make
critical decisions, such as whether or not to adopt HTMX.
Competition is good. HTMX is thought-provoking, but I think its great because it
forces developers to entertain new and novel ideas. Developers can often be wary
and cautious of new technologies, since it might not be solving a personal
problem they are already facing. But for the developers that are resonating with
HTMX, there is an enthusiastic group of developers who are starting to use it in
production.
I have not personally deployed a production application using HTMX, but I am
really excited to try it. It would solve a personal problem with my engineering
team and also allow me to simplify the build process of deploying applications.
Those two things are important to me, and HTMX seems like a great fit.